AP Statistics Curriculum 2007 ANOVA 2Way
From Socr
m (→ General Advance-Placement (AP) Statistics Curriculum - Two-Way Analysis of Variance (ANOVA)) |
|||
| Line 1: | Line 1: | ||
==[[AP_Statistics_Curriculum_2007 | General Advance-Placement (AP) Statistics Curriculum]] - Two-Way Analysis of Variance (ANOVA) == | ==[[AP_Statistics_Curriculum_2007 | General Advance-Placement (AP) Statistics Curriculum]] - Two-Way Analysis of Variance (ANOVA) == | ||
| - | In the [[ | + | In the [[AP_Statistics_Curriculum_2007_ANOVA_1Way |previous section]], we discussed statistical inference in comparing ''k'' independent samples separated by a single (grouping) factor. Now we will discuss variance decomposition of data into (independent/orthogonal) components when we have two (grouping) factors. Hence, this procedure called '''Two-Way Analysis of Variance'''. |
===Motivational Example=== | ===Motivational Example=== | ||
Revision as of 01:15, 20 February 2008
Contents |
General Advance-Placement (AP) Statistics Curriculum - Two-Way Analysis of Variance (ANOVA)
In the previous section, we discussed statistical inference in comparing k independent samples separated by a single (grouping) factor. Now we will discuss variance decomposition of data into (independent/orthogonal) components when we have two (grouping) factors. Hence, this procedure called Two-Way Analysis of Variance.
Motivational Example
Suppose 5 varieties of peas are currently being tested by a large agribusiness cooperative to determine which is best suited for production. A field was divided into 20 plots, with each variety of peas planted in four plots. The yields (in bushels of peas) produced from each plot are shown in two identical forms in the tables below.
| Variety of Pea | ||||
| A | B | C | D | E |
| 26.2 | 29.2 | 29.1 | 21.3 | 20.1 |
| 24.3 | 28.1 | 30.8 | 22.4 | 19.3 |
| 21.8 | 27.3 | 33.9 | 24.3 | 19.9 |
| 28.1 | 31.2 | 32.8 | 21.8 | 22.1 |
| A | 26.2,24.3,21.8,28.1 |
| B | 29.2,28.1,27.3,31.2 |
| C | 29.1,30.8,33.9,32.8 |
| D | 21.3,22.4,24.3,21.8 |
| E | 20.1,19.3,19.9,22.1 |
Using the SOCR Charts (see SOCR Box-and-Whisker Plot Activity and Dot Plot Activity), we can generate plots that enable us to compare visually the yields of the 5 different types peas.

Two-Way ANOVA Calculations
Let's make the following notation:
- yi,j = the measurement from group i, observation-index j.
- k = number of groups
- ni = number of observations in group i
- n = total number of observations,
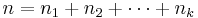
- The group mean for group i is:
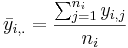
- The grand mean is:
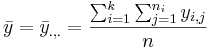
- Two-way Model: yi,j,k = μ + τi + βj + γi,j + εi,j,k, for all
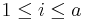 ,
, 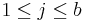 and
and 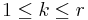 . Here μ is the overall mean response, τi is the effect due to the ith level of factor A, βj is the effect due to the jth level of factor B and γi,j is the effect due to any interaction between the ith level of factor A and the jth level of factor B.
. Here μ is the overall mean response, τi is the effect due to the ith level of factor A, βj is the effect due to the jth level of factor B and γi,j is the effect due to any interaction between the ith level of factor A and the jth level of factor B.
When an  factorial experiment is conducted with an equal number of observation per treatment combination, and where AB represents the interaction between A and B, the total (corrected) sum of squares is partitioned as:
factorial experiment is conducted with an equal number of observation per treatment combination, and where AB represents the interaction between A and B, the total (corrected) sum of squares is partitioned as:
Hypotheses
There are three sets of hypotheses with the two-way ANOVA.
The null hypotheses for each of the sets
- The population means of the first factor are equal. This is like the one-way ANOVA for the row factor.
- The population means of the second factor are equal. This is like the one-way ANOVA for the column factor.
- There is no interaction between the two factors. This is similar to performing a test for independence with contingency tables.
Factors
The two independent variables in a two-way ANOVA are called factors (denoted by A and B). The idea is that there are two variables, factors, which affect the dependent variable (Y). Each factor will have two or more levels within it, and the degrees of freedom for each factor is one less than the number of levels.
Treatment Groups
Treatement Groups are formed by making all possible combinations of the two factors. For example, if the first factor has 5 levels and the second factor has 6 levels, then there will be 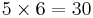 different treatment groups.
different treatment groups.
Main Effect
The main effect involves the independent variables one at a time. The interaction is ignored for this part. Just the rows or just the columns are used, not mixed. This is the part which is similar to the one-way analysis of variance. Each of the variances calculated to analyze the main effects are like the between variances
Interaction Effect
The interaction effect is the effect that one factor has on the other factor. The degrees of freedom here is the product of the two degrees of freedom for each factor.
Within Variation
The Within variation is the sum of squares within each treatment group. You have one less than the sample size (remember all treatment groups must have the same sample size for a two-way ANOVA) for each treatment group. The total number of treatment groups is the product of the number of levels for each factor. The within variance is the within variation divided by its degrees of freedom. The within group is also called the error.
F-Tests
There is an F-test for each of the hypotheses, and the F-test is the mean square for each main effect and the interaction effect divided by the within variance. The numerator degrees of freedom come from each effect, and the denominator degrees of freedom is the degrees of freedom for the within variance in each case.
Two-Way ANOVA Table
It is assumed that main effect A has a levels (and A = a-1 df), main effect B has b levels (and B = b-1 df), n is the sample size of each treatment, and 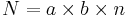 is the total sample size. Notice the overall degrees of freedom is once again one less than the total sample size.
is the total sample size. Notice the overall degrees of freedom is once again one less than the total sample size.
Source SS df MS F Main Effect A given A, a-1 SS / df MS(A) / MS(W) Main Effect B given B, b-1 SS / df MS(B) / MS(W) Interaction Effect given A*B, (a-1)(b-1) SS / df MS(A*B) / MS(W) Within given N - ab, ab(n-1) SS / df Total sum of others N - 1, abn - 1
| Variance Source | Degrees of Freedom (df) | Sum of Squares (SS) | Mean Sum of Squares (MS) | F-Statistics | P-value | ||||||
| Main Effect A | df(A)=a-1 | 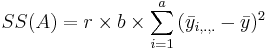 | 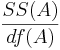 | 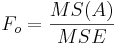 | P(F(df(A),df(E)) > Fo) | ||||||
| Main Effect B | df(B)=b-1 | 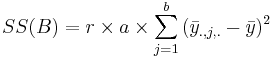 | 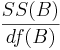 | 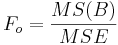 | P(F(df(B),df(E)) > Fo) | A vs.B Interaction | df(AB)=(a-1)(b-1) | 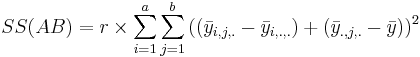 | Failed to parse (syntax error): {SS(AB)\over df(AB)}} | 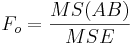 | P(F(df(AB),df(E)) > Fo) |
| Error | 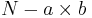 | 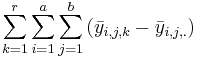 | 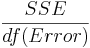 | ||||||||
| Total | N-1 | 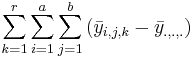 | ANOVA Activity |
To compute the difference between the means, we will compare each group mean to the grand mean.
SOCR ANOVA Calculations
SOCR Analyses provide the tools to compute the 1-way ANOVA. For example, the ANOVA for the peas data above may be easily computed - see the image below. Note that SOCR ANOVA requires the data to be entered in this format:

Examples
TBD
Two-Way ANOVA Conditions
The Two-way ANOVA is valid if:
- The populations from which the samples were obtained must be normally or approximately normally distributed.
- The samples must be independent.
- The variances of the populations must be equal.
- The groups must have the same sample size.
References
- SOCR Home page: http://www.socr.ucla.edu
Translate this page:
