AP Statistics Curriculum 2007 Contingency Indep
From Socr
| Line 2: | Line 2: | ||
=== Contingency Tables: Independence and Homogeneity === | === Contingency Tables: Independence and Homogeneity === | ||
| - | |||
| - | |||
| - | + | The chi-square test may also be used to assess independence and association between variables. | |
| - | + | ||
| - | + | ==Motivational example== | |
| + | Suppose 200 randomly selected cancer patients were asked if their primary diagnosis was Brain cancer and if they owned a cell phone before their diagnosis. The results are presented in the table below. | ||
| - | == | + | Suppose we want to analyze the association, if any, between ''brain cancer'' and ''cell phone use''. |
| - | + | The 2x2 table below lists two possible outcomes for each variable (each variable is dichotomous). We have the following population parameters: | |
| + | : P(CP|BC) = true probability of owning a cell phone (CP) given that the patient had brain cancer (BC). This chance may be estimated by P(CP|BC) = 0.72. | ||
| - | + | : P(CP|NBC) = true probability of owning a cell phone given that the patient had another cancer, which is estimated by P(CP|NBC) = 0.46 | |
| - | == | + | <center> |
| - | + | {| class="wikitable" style="text-align:center; width:25%" border="1" | |
| + | |- | ||
| + | | || || colspan=3| '''Brain cancer''' | ||
| + | |- | ||
| + | | || || '''Yes''' || '''No''' || '''Total''' | ||
| + | |- | ||
| + | | rowspan=3| '''Cell Phone Use''' || '''Yes''' || 18 || 80 || 98 | ||
| + | |- | ||
| + | | '''No''' || 7 || 95 || 102 | ||
| + | |- | ||
| + | | '''Total''' || 25 || 175 || 200 | ||
| + | |} | ||
| + | </center> | ||
| - | == | + | Does it seem like there is an association between brain cancer and cell phone use? |
| - | + | Of the brain cancer patients 18/25 = 0.72, owned a cell phone before their diagnosis. | |
| + | ''P(CP|BC) = 0.72'', estimated probability of owning a cell phone given that the patient has brain cancer. | ||
| - | + | Of the other cancer patients, 80/175 = 0.46, owned a cell phone before their diagnosis. | |
| - | + | ''P(CP|NBC) = 0.46'', estimated probability of owning a cell phone given that the patient has another cancer. | |
| - | === | + | |
| - | + | ==Calculations== | |
| + | |||
| + | Suppose there were ''N = 1064'' data measurements with ''Observed(Tall) = 787'' and ''Observed(Dwarf) = 277''. These are the O’s (observed values). To calculate the E’s (expected values), we will take the hypothesized proportions under <math>H_o</math> and multiply them by the total sample size ''N''. Expected(Tall) = (0.75)(1064) = 798 and Expected(Dwarf) = (0.25)(1064) = 266. Quickly check to see if the expected total = N = 1064. | ||
| + | |||
| + | * The hypotheses: | ||
| + | : <math>H_o</math>: there is no association between variable 1 and variable 2 (independence) | ||
| + | |||
| + | : <math>H_a</math>: there is an association between variable 1 and variable 2 (dependence) | ||
| + | |||
| + | * Test statistics: | ||
| + | The test statistic: | ||
| + | |||
| + | :<math>\chi_o^2 = \sum_{all-categories}{(O-E)^2 \over E} \sim \chi_{(df=(\# rows – 1)(\# col – 1))}^2</math> | ||
| + | |||
| + | : Expected cell counts can be calculated by | ||
| + | :: <math>E = { (row-toral)(column-total)\over grand-total}</math> | ||
| + | with ''df = (# rows – 1)(# col – 1)''. | ||
| + | |||
| + | * P-values and critical values for the [http://socr.stat.ucla.edu/htmls/SOCR_Distributions.html Chi-Square distribution may be easily computed using SOCR Distributions]. | ||
| + | |||
| + | * Results: | ||
| + | |||
| + | |||
| + | * [[SOCR_EduMaterials_AnalysisActivities_Chi_Goodness |SOCR Chi-square Calculations]]: | ||
| + | |||
| + | <center>[[Image:SOCR_EBook_Dinov_ChiSquare_030108_Fig1.jpg|500px]]</center> | ||
| + | |||
| + | ==Examples== | ||
| + | |||
| + | |||
| + | ==Applications== | ||
| - | |||
<hr> | <hr> | ||
| - | + | ==References== | |
* TBD | * TBD | ||
Revision as of 02:01, 4 March 2008
Contents |
General Advance-Placement (AP) Statistics Curriculum - Contingency Tables: Independence and Homogeneity
Contingency Tables: Independence and Homogeneity
The chi-square test may also be used to assess independence and association between variables.
Motivational example
Suppose 200 randomly selected cancer patients were asked if their primary diagnosis was Brain cancer and if they owned a cell phone before their diagnosis. The results are presented in the table below.
Suppose we want to analyze the association, if any, between brain cancer and cell phone use. The 2x2 table below lists two possible outcomes for each variable (each variable is dichotomous). We have the following population parameters:
- P(CP|BC) = true probability of owning a cell phone (CP) given that the patient had brain cancer (BC). This chance may be estimated by P(CP|BC) = 0.72.
- P(CP|NBC) = true probability of owning a cell phone given that the patient had another cancer, which is estimated by P(CP|NBC) = 0.46
| Brain cancer | ||||
| Yes | No | Total | ||
| Cell Phone Use | Yes | 18 | 80 | 98 |
| No | 7 | 95 | 102 | |
| Total | 25 | 175 | 200 | |
Does it seem like there is an association between brain cancer and cell phone use? Of the brain cancer patients 18/25 = 0.72, owned a cell phone before their diagnosis. P(CP|BC) = 0.72, estimated probability of owning a cell phone given that the patient has brain cancer.
Of the other cancer patients, 80/175 = 0.46, owned a cell phone before their diagnosis. P(CP|NBC) = 0.46, estimated probability of owning a cell phone given that the patient has another cancer.
Calculations
Suppose there were N = 1064 data measurements with Observed(Tall) = 787 and Observed(Dwarf) = 277. These are the O’s (observed values). To calculate the E’s (expected values), we will take the hypothesized proportions under Ho and multiply them by the total sample size N. Expected(Tall) = (0.75)(1064) = 798 and Expected(Dwarf) = (0.25)(1064) = 266. Quickly check to see if the expected total = N = 1064.
- The hypotheses:
- Ho: there is no association between variable 1 and variable 2 (independence)
- Ha: there is an association between variable 1 and variable 2 (dependence)
- Test statistics:
The test statistic:
- Failed to parse (lexing error): \chi_o^2 = \sum_{all-categories}{(O-E)^2 \over E} \sim \chi_{(df=(\# rows – 1)(\# col – 1))}^2
- Expected cell counts can be calculated by
-
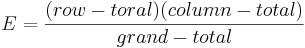
with df = (# rows – 1)(# col – 1).
- P-values and critical values for the Chi-Square distribution may be easily computed using SOCR Distributions.
- Results:

Examples
Applications
References
- TBD
- SOCR Home page: http://www.socr.ucla.edu
Translate this page:
