AP Statistics Curriculum 2007 EDA Pics
From Socr
(→Pictures of Data) |
(→Pictures of Data: Fixed a bad notation of "sample-size") |
||
| Line 5: | Line 5: | ||
* For '''quantitative''' variables, we need to make classes (meaningful intervals) first. To accomplish this, we need to separate (or bin) the quantitative data into classes. | * For '''quantitative''' variables, we need to make classes (meaningful intervals) first. To accomplish this, we need to separate (or bin) the quantitative data into classes. | ||
* For qualitative variables, we need to use the frequency counts instead of the native measurements as the latter may not even have a natural ordering (so binning the variables in classes may not be possible). | * For qualitative variables, we need to use the frequency counts instead of the native measurements as the latter may not even have a natural ordering (so binning the variables in classes may not be possible). | ||
| - | * How to define the number of bins or classes? One common ''rule of thumb'' is that the number of classes should be close to <math>\sqrt{sample | + | * How to define the number of bins or classes? One common ''rule of thumb'' is that the number of classes should be close to <math>\sqrt{\texttt{sample size}}.</math> For accurate interpretation of data, it is important that all classes (or bins) are of equal width. Once we have our classes, we can create a frequency/relative frequency table or histogram. |
===Example=== | ===Example=== | ||
Revision as of 03:53, 7 April 2008
Contents |
General Advance-Placement (AP) Statistics Curriculum - Pictures of Data
Pictures of Data
There are varieties of graphs and plots that may be used to display data.
- For quantitative variables, we need to make classes (meaningful intervals) first. To accomplish this, we need to separate (or bin) the quantitative data into classes.
- For qualitative variables, we need to use the frequency counts instead of the native measurements as the latter may not even have a natural ordering (so binning the variables in classes may not be possible).
- How to define the number of bins or classes? One common rule of thumb is that the number of classes should be close to
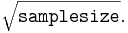 For accurate interpretation of data, it is important that all classes (or bins) are of equal width. Once we have our classes, we can create a frequency/relative frequency table or histogram.
For accurate interpretation of data, it is important that all classes (or bins) are of equal width. Once we have our classes, we can create a frequency/relative frequency table or histogram.
Example
People who are concerned about their health may prefer hot dogs that are low in salt and calories. The Hot dogs data file contains data on the sodium and calories contained in each of 54 major hot dog brands. The hot dogs are also classified by type: beef, poultry, and meat (mostly pork and beef, but up to 15% poultry meat). For now we will focus on the calories of these sampled hotdogs.
Frequency Histogram Charts
- Using SOCR Charts and the Charts activities you can produce a number of interesting graphical summaries for this hotdogs dataset.
- The histogram of the Calorie content of all hotdogs in shown in the image below. Note the clear separation of the calories into 3 distinct sub-populations. Could this be related to the type of meat in the hotdogs?

- The histogram of the Sodium content of all hotdogs in shown in the image below. What patterns in this histogram can you identify? Try to explain!

Box and Whisker Plots
- Using SOCR Charts and the Box-And-Whisker Charts activities you can produce a number of interesting graphical summaries for this hotdogs dataset.
- The graph below shows the box and whisker plot of the Calorie content for all 3 types of hotdogs.

- The graph below shows the box and whisker plot of the Sodium (salt) content for all 3 types of hotdogs.

Dot Plots
- Using SOCR Charts and the Dot Plot Charts activities you can produce a number of interesting graphical summaries for this hotdogs dataset.
- The graph below shows the dot-plot of the Calorie content for all 3 types of hotdogs.

- The graph below shows the dot-plot of the Sodium content for all 3 types of hotdogs.

Stem-and-Leaf Plots
Stem-and-leaf plot is a method for presenting quantitative data in a graphical format, similar to a histogram. It is used to assist in visualizing the shape of a distribution. Stem-and-leaf plots are useful tools in exploratory data analysis. Unlike histograms, stem-and-leaf plots retain the original data to at least two significant digits, and put the data in order, which simplifies the move to order-based inference and non-parametric statistics. A basic stem-plot contains two columns separated by a vertical line. The left column contains the stems and the right column contains the leaves.
- Construction: To construct a stem-and-leaf plot, the observations must first be sorted in ascending order. Then, it must be determined what the stems will represent and what the leaves will represent. Frequently, the leaf contains the last digit of the number and the stem contains all of the other digits. Sometimes, the data values may be rounded to a particular place value (such as the hundreds place) that will be used for the leaves. The remaining digits to the left of the rounded place value are used as the stems.
- Example: The stem-and-leaf plot for the calorie variable of the Hot dogs data is shown below.
- Legend: Stem-and-leaf of Calories, N = 54; Leaf Unit = 1.0
| 8 | 67 | |
| 9 | 49 | |
| 10 | 22677 | |
| 11 | 13 | |
| 12 | 9 | |
| 13 | 1225556899 | |
| 14 | 01234667899 | |
| 15 | 223378 | |
| 16 | ||
| 17 | 235569 | |
| 18 | 1246 | |
| 19 | 00015 |
Summary
- Histograms can handle large data sets, but can’t tell exact data values and require the user to set-up classes
- Dot plots can get a better picture of data values, but can’t handle large data sets
- Stem and leaf plots can see actual data values, but can’t handle large data sets
References
- SOCR Home page: http://www.socr.ucla.edu
Translate this page:
