AP Statistics Curriculum 2007 Estim L Mean
From Socr
(added the illustration of CI (Figure 3)) |
m (→Example: typo) |
||
| (11 intermediate revisions not shown) | |||
| Line 4: | Line 4: | ||
=== Point Estimation of a Population Mean=== | === Point Estimation of a Population Mean=== | ||
| - | For any process, the population mean may be estimated by a (large) sample average. That is the sample average <math>\overline{X_n}={1\over n}\sum_{i=1}^n{X_i}</math>, constructed from a random sample of the process {<math>X_1, X_2, X_3, \cdots , X_n</math>}, is an [http://en.wikipedia.org/wiki/Estimator_bias unbiased] estimate of the population mean <math>\mu</math>, if it exists! Note that the [[AP_Statistics_Curriculum_2007_EDA_Center | sample average may be susceptible to outliers]]. | + | For any process, the population mean may be estimated by a (large) sample average. That is the sample average <math>\overline{X_n}={1\over n}\sum_{i=1}^n{X_i}</math>, constructed from a random sample of the process {<math>X_1, X_2, X_3, \cdots , X_n</math>}, which is an [http://en.wikipedia.org/wiki/Estimator_bias unbiased] estimate of the population mean <math>\mu</math>, if it exists! Note that the [[AP_Statistics_Curriculum_2007_EDA_Center | sample average may be susceptible to outliers]]. |
| + | |||
| + | ===Definition: Confidence Interval=== | ||
| + | A type of interval that contains the true value of a parameter of interest for <math>(1-\alpha)100</math>% of samples taken is called a ''<math>(1-\alpha)100</math>% confidence interval'' for that parameter, and the ends of the CI are called ''confidence limits''. For example, a 95% confidence interval (<math>\alpha=0.05</math>) for the population mean is an interval estimate (range of values) that contains the true population mean for 95% of samples taken from the same population. | ||
===Interval Estimation of a Population Mean=== | ===Interval Estimation of a Population Mean=== | ||
[[Image:SOCR_EBook_Dinov_Estimates_L_Mean_121208_Fig3.png|200px|thumbnail|right]] | [[Image:SOCR_EBook_Dinov_Estimates_L_Mean_121208_Fig3.png|200px|thumbnail|right]] | ||
| - | For large samples, interval | + | For large samples, interval estimations of the population means (or Confidence Intervals) are constructed as follows. Choose a confidence level <math>(1-\alpha)100%</math>, where <math>\alpha</math> is small (e.g., 0.1, 0.05, 0.025, 0.01, 0.001, etc.). Then a <math>(1-\alpha)100%</math> confidence interval for <math>\mu</math> will be |
: <math>CI(\alpha): \overline{x} \pm z_{\alpha\over 2} E,</math> | : <math>CI(\alpha): \overline{x} \pm z_{\alpha\over 2} E,</math> | ||
| - | * The ''' | + | * The '''Error''' term, E, is defined as |
<math>E = \begin{cases}{\sigma\over\sqrt{n}},& \texttt{for-known}-\sigma,\\ | <math>E = \begin{cases}{\sigma\over\sqrt{n}},& \texttt{for-known}-\sigma,\\ | ||
{SE},& \texttt{for-unknown}-\sigma.\end{cases}</math> | {SE},& \texttt{for-unknown}-\sigma.\end{cases}</math> | ||
| - | * The '''Standard Error''' of the | + | * The '''Standard Error''' of the estimated <math>\overline {x}</math> is obtained by replacing the unknown population standard deviation by the sample standard deviation: |
<math>SE(\overline {x}) = {1\over \sqrt{n}} \sqrt{\sum_{i=1}^n{(x_i-\overline{x})^2\over n-1}}</math> | <math>SE(\overline {x}) = {1\over \sqrt{n}} \sqrt{\sum_{i=1}^n{(x_i-\overline{x})^2\over n-1}}</math> | ||
| Line 27: | Line 30: | ||
** Population under study | ** Population under study | ||
** Confidence Interval with appropriate units | ** Confidence Interval with appropriate units | ||
| + | |||
| + | ===Assumptions=== | ||
| + | The [[AP_Statistics_Curriculum_2007_Limits_CLT | Central Limit Theorem]] guarantees that for large-samples, the method above provides a valid recipe for constructing a confidence interval for the population mean, no matter what the distribution of the observed data may be. Of course, for significantly non-Normal distributions, we may need to increase the sample size to guarantee that the sampling distribution of the mean is approximately Normal! | ||
===Example=== | ===Example=== | ||
| - | Market researchers use the ''number of sentences per advertisement'' as a measure of readability for magazine advertisements. A random sample of the number of sentences found in 30 magazine advertisements is listed. Use this sample to find ''point estimate'' for the population mean <math>\mu</math>. | + | Market researchers use the ''number of sentences per advertisement'' as a measure of readability for magazine advertisements. A random sample of the number of sentences found in 30 magazine advertisements is listed. Use this sample to find ''point estimate'' for the population mean <math>\mu</math>. (See the [[AP_Statistics_Curriculum_2007_Estim_L_Mean_Table1 |data in (transposed) column format]]) |
<center> | <center> | ||
{| class="wikitable" style="text-align:center; width:75%" border="1" | {| class="wikitable" style="text-align:center; width:75%" border="1" | ||
| Line 37: | Line 43: | ||
</center> | </center> | ||
| - | A ''confidence interval estimate'' of <math>\mu</math> is a range of values used to estimate a population parameter (interval estimates are normally used more than point estimates because it is very unlikely that the sample mean would match exactly with the population mean) The interval estimate uses a margin of error about the point estimate. For example if you have a point estimate of 12. 25 with a margin of error of 1.75, then the interval estimate would be (10.5 to 14). | + | A ''confidence interval estimate'' of <math>\mu</math> is a range of values used to estimate a population parameter (interval estimates are normally used more than point estimates because it is very unlikely that the sample mean would match exactly with the population mean). The interval estimate uses a margin of error about the point estimate. For example if you have a point estimate of 12.25 with a margin of error of 1.75, then the interval estimate would be (10.5 to 14). |
Before you find an interval estimate, you should first determine how confident you want to be that your interval estimate contains the population mean. | Before you find an interval estimate, you should first determine how confident you want to be that your interval estimate contains the population mean. | ||
* [[AP_Statistics_Curriculum_2007_Normal_Critical | Recall these critical values for Standard Normal Distribution]]: | * [[AP_Statistics_Curriculum_2007_Normal_Critical | Recall these critical values for Standard Normal Distribution]]: | ||
| - | :80% confidence (0.80), <math>\alpha=0.1</math>, [http://socr.ucla.edu/Applets.dir/Z-table.html z = 1.28] | + | :80% confidence (0.80), <math>{\alpha \over 2}=0.1</math>, [http://socr.ucla.edu/Applets.dir/Z-table.html z = 1.28] |
| - | :90% confidence (0.90), <math>\alpha=0.05</math>, [http://socr.ucla.edu/Applets.dir/Z-table.html z = 1.645] | + | :90% confidence (0.90), <math>{\alpha \over 2}=0.05</math>, [http://socr.ucla.edu/Applets.dir/Z-table.html z = 1.645] |
| - | :95% confidence (0.95), <math>\alpha=0.025</math>, [http://socr.ucla.edu/Applets.dir/Z-table.html z = 1.96] | + | :95% confidence (0.95), <math>{\alpha \over 2}=0.025</math>, [http://socr.ucla.edu/Applets.dir/Z-table.html z = 1.96] |
| - | :99% confidence (0.99), <math>\alpha=0.005</math>, [http://socr.ucla.edu/Applets.dir/Z-table.html z = 2.575] | + | :99% confidence (0.99), <math>{\alpha \over 2}=0.005</math>, [http://socr.ucla.edu/Applets.dir/Z-table.html z = 2.575] |
====Known Variance==== | ====Known Variance==== | ||
Suppose that we know the variance for the ''number of sentences per advertisement'' example above is known to be 256 (so the population standard deviation is <math>\sigma=16</math>). | Suppose that we know the variance for the ''number of sentences per advertisement'' example above is known to be 256 (so the population standard deviation is <math>\sigma=16</math>). | ||
| - | * For <math>\alpha=0.1</math>, the <math>80% CI(\mu)</math> is constructed by: | + | * For <math>{\alpha \over 2}=0.1</math>, the <math>80% CI(\mu)</math> is constructed by: |
<center> <math>\overline{x}\pm 1.28SE(\overline{x})=14.77 \pm 1.28{16\over \sqrt{30}}=[11.03;18.51]</math></center> | <center> <math>\overline{x}\pm 1.28SE(\overline{x})=14.77 \pm 1.28{16\over \sqrt{30}}=[11.03;18.51]</math></center> | ||
| - | * For <math>\alpha=0.05</math>, the <math>90% CI(\mu)</math> is constructed by: | + | * For <math>{\alpha \over 2}=0.05</math>, the <math>90% CI(\mu)</math> is constructed by: |
<center> <math>\overline{x}\pm 1.645SE(\overline{x})=14.77 \pm 1.645{16\over \sqrt{30}}=[9.96;19.57]</math></center> | <center> <math>\overline{x}\pm 1.645SE(\overline{x})=14.77 \pm 1.645{16\over \sqrt{30}}=[9.96;19.57]</math></center> | ||
| - | * For <math>\alpha=0.005</math>, the <math>99% CI(\mu)</math> is constructed by: | + | * For <math>{\alpha \over 2}=0.005</math>, the <math>99% CI(\mu)</math> is constructed by: |
<center> <math>\overline{x}\pm 2.575SE(\overline{x})=14.77 \pm 2.575{16\over \sqrt{30}}=[7.24;22.29]</math></center> | <center> <math>\overline{x}\pm 2.575SE(\overline{x})=14.77 \pm 2.575{16\over \sqrt{30}}=[7.24;22.29]</math></center> | ||
| Line 64: | Line 70: | ||
Suppose that we do '''not''' know the variance for the ''number of sentences per advertisement'' but use the sample variance 273 as an estimate (so the sample standard deviation is <math>s=\hat{\sigma}=16.54</math>). | Suppose that we do '''not''' know the variance for the ''number of sentences per advertisement'' but use the sample variance 273 as an estimate (so the sample standard deviation is <math>s=\hat{\sigma}=16.54</math>). | ||
| - | * For <math>\alpha | + | * For <math>{\alpha \over 2}</math>, the <math>80% CI(\mu)</math> is constructed by: |
<center> <math>\overline{x}\pm 1.28SE(\overline{x})=14.77 \pm 1.28{16.54\over \sqrt{30}}=[10.90;18.63]</math></center> | <center> <math>\overline{x}\pm 1.28SE(\overline{x})=14.77 \pm 1.28{16.54\over \sqrt{30}}=[10.90;18.63]</math></center> | ||
| - | * For <math>\alpha=0.05</math>, the <math>90% CI(\mu)</math> is constructed by: | + | * For <math>{\alpha \over 2}=0.05</math>, the <math>90% CI(\mu)</math> is constructed by: |
<center> <math>\overline{x}\pm 1.645SE(\overline{x})=14.77 \pm 1.645{16.54\over \sqrt{30}}=[9.80;19.73]</math></center> | <center> <math>\overline{x}\pm 1.645SE(\overline{x})=14.77 \pm 1.645{16.54\over \sqrt{30}}=[9.80;19.73]</math></center> | ||
| - | * For <math>\alpha=0.005</math>, the <math> | + | * For <math>{\alpha \over 2}=0.005</math>, the <math>99% CI(\mu)</math> is constructed by: |
<center> <math>\overline{x}\pm 2.575SE(\overline{x})=14.77 \pm 2.575{16.54\over \sqrt{30}}=[6.99;22.54]</math></center> | <center> <math>\overline{x}\pm 2.575SE(\overline{x})=14.77 \pm 2.575{16.54\over \sqrt{30}}=[6.99;22.54]</math></center> | ||
Notice the increase of the CI's (directly related to the decrease of <math>\alpha</math>) reflecting our choice for higher confidence. | Notice the increase of the CI's (directly related to the decrease of <math>\alpha</math>) reflecting our choice for higher confidence. | ||
| + | |||
| + | You can use the [http://www.socr.ucla.edu/htmls/ana/ConfidenceInterval_Analysis.html SOCR CI Analysis Applet] to compute these interval estimates. | ||
===Hands-on Activities=== | ===Hands-on Activities=== | ||
| Line 83: | Line 91: | ||
<hr> | <hr> | ||
| - | === | + | ===[[EBook_Problems_Estim_L_Mean|Problems]]=== |
<hr> | <hr> | ||
Current revision as of 17:25, 20 May 2011
Contents |
General Advance-Placement (AP) Statistics Curriculum - Estimating a Population Mean: Large Samples
This section discusses how to find point and interval estimates when the sample-sizes are large. For most applications, sample-sizes exceeding 100 may be considered as large. However, in practice even samples larger than 30 may be considered large. Yet, sometimes, samples must be > 1,000, or even 100,000 to be considered large. The next section presents the estimation for small-samples.
Point Estimation of a Population Mean
For any process, the population mean may be estimated by a (large) sample average. That is the sample average 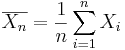 , constructed from a random sample of the process {
, constructed from a random sample of the process {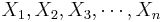 }, which is an unbiased estimate of the population mean μ, if it exists! Note that the sample average may be susceptible to outliers.
}, which is an unbiased estimate of the population mean μ, if it exists! Note that the sample average may be susceptible to outliers.
Definition: Confidence Interval
A type of interval that contains the true value of a parameter of interest for (1 − α)100% of samples taken is called a (1 − α)100% confidence interval for that parameter, and the ends of the CI are called confidence limits. For example, a 95% confidence interval (α = 0.05) for the population mean is an interval estimate (range of values) that contains the true population mean for 95% of samples taken from the same population.
Interval Estimation of a Population Mean

For large samples, interval estimations of the population means (or Confidence Intervals) are constructed as follows. Choose a confidence level (1 − α)100%, where α is small (e.g., 0.1, 0.05, 0.025, 0.01, 0.001, etc.). Then a (1 − α)100% confidence interval for μ will be
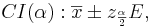
- The Error term, E, is defined as

- The Standard Error of the estimated
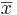 is obtained by replacing the unknown population standard deviation by the sample standard deviation:
is obtained by replacing the unknown population standard deviation by the sample standard deviation:
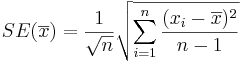
-
 is the Critical Value for a Standard Normal distribution at
is the Critical Value for a Standard Normal distribution at 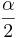 .
.
- Important Properties of a CI Conclusion:
- Confidence Level (alpha)
- Parameter of Interest
- Variable of Interest
- Population under study
- Confidence Interval with appropriate units
Assumptions
The Central Limit Theorem guarantees that for large-samples, the method above provides a valid recipe for constructing a confidence interval for the population mean, no matter what the distribution of the observed data may be. Of course, for significantly non-Normal distributions, we may need to increase the sample size to guarantee that the sampling distribution of the mean is approximately Normal!
Example
Market researchers use the number of sentences per advertisement as a measure of readability for magazine advertisements. A random sample of the number of sentences found in 30 magazine advertisements is listed. Use this sample to find point estimate for the population mean μ. (See the data in (transposed) column format)
| 16 | 9 | 14 | 11 | 17 | 12 | 99 | 18 | 13 | 12 | 5 | 9 | 17 | 6 | 11 | 17 | 18 | 20 | 6 | 14 | 7 | 11 | 12 | 5 | 18 | 6 | 4 | 13 | 11 | 12 |
A confidence interval estimate of μ is a range of values used to estimate a population parameter (interval estimates are normally used more than point estimates because it is very unlikely that the sample mean would match exactly with the population mean). The interval estimate uses a margin of error about the point estimate. For example if you have a point estimate of 12.25 with a margin of error of 1.75, then the interval estimate would be (10.5 to 14).
Before you find an interval estimate, you should first determine how confident you want to be that your interval estimate contains the population mean.
- 80% confidence (0.80),
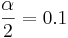 , z = 1.28
, z = 1.28
- 90% confidence (0.90),
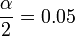 , z = 1.645
, z = 1.645
- 95% confidence (0.95),
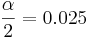 , z = 1.96
, z = 1.96
- 99% confidence (0.99),
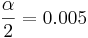 , z = 2.575
, z = 2.575
Known Variance
Suppose that we know the variance for the number of sentences per advertisement example above is known to be 256 (so the population standard deviation is σ = 16).
- For , the 80%CI(μ) is constructed by:
![\overline{x}\pm 1.28SE(\overline{x})=14.77 \pm 1.28{16\over \sqrt{30}}=[11.03;18.51]](/socr/uploads/math/9/f/d/9fd7e8ded455715e294f3b8f9a4694df.png)
- For , the 90%CI(μ) is constructed by:
![\overline{x}\pm 1.645SE(\overline{x})=14.77 \pm 1.645{16\over \sqrt{30}}=[9.96;19.57]](/socr/uploads/math/5/8/6/586a2650b916bbd1504606e05f9b9cd7.png)
- For , the 99%CI(μ) is constructed by:
![\overline{x}\pm 2.575SE(\overline{x})=14.77 \pm 2.575{16\over \sqrt{30}}=[7.24;22.29]](/socr/uploads/math/c/d/3/cd3a36f9e588a902a591c2c678a2635e.png)
Notice the increase of the CI's (directly related to the decrease of α) reflecting our choice for higher confidence.
Unknown Variance
Suppose that we do not know the variance for the number of sentences per advertisement but use the sample variance 273 as an estimate (so the sample standard deviation is 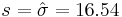 ).
).
- For , the 80%CI(μ) is constructed by:
![\overline{x}\pm 1.28SE(\overline{x})=14.77 \pm 1.28{16.54\over \sqrt{30}}=[10.90;18.63]](/socr/uploads/math/0/2/b/02b2f72e6e402cf9c04be3f926928e9e.png)
- For , the 90%CI(μ) is constructed by:
![\overline{x}\pm 1.645SE(\overline{x})=14.77 \pm 1.645{16.54\over \sqrt{30}}=[9.80;19.73]](/socr/uploads/math/7/d/e/7de29d849942f760772369aee447acc1.png)
- For , the 99%CI(μ) is constructed by:
![\overline{x}\pm 2.575SE(\overline{x})=14.77 \pm 2.575{16.54\over \sqrt{30}}=[6.99;22.54]](/socr/uploads/math/d/2/0/d200400d0ac99ae47bab3b0b3b407d0b.png)
Notice the increase of the CI's (directly related to the decrease of α) reflecting our choice for higher confidence.
You can use the SOCR CI Analysis Applet to compute these interval estimates.
Hands-on Activities
- See the SOCR Confidence Interval Experiment.
- Sample statistics, like the sample-mean and the sample-variance, may be easily obtained using SOCR Charts. The images below illustrate this functionality (based on the Bar-Chart and Index-Chart) using the 30 observations of the number of sentences per advertisement, reported above.


Problems
- SOCR Home page: http://www.socr.ucla.edu
Translate this page:
