AP Statistics Curriculum 2007 Estim MOM MLE
From Socr
(→ General Advance-Placement (AP) Statistics Curriculum - Method of Moments and Maximum Likelihood Estimation) |
m (→MOM Proportion Example: typo) |
||
| Line 18: | Line 18: | ||
* Hypothetical solution: Suppose we observe the following sequence of outcomes ''{T,H,T,H,H,T,H,H}''. Using the MOM protocol we obtain: | * Hypothetical solution: Suppose we observe the following sequence of outcomes ''{T,H,T,H,H,T,H,H}''. Using the MOM protocol we obtain: | ||
** There is one parameter of interest ''p=P(H)'' and the process is a [[AP_Statistics_Curriculum_2007_Distrib_Binomial |Binomial experiment]]. | ** There is one parameter of interest ''p=P(H)'' and the process is a [[AP_Statistics_Curriculum_2007_Distrib_Binomial |Binomial experiment]]. | ||
| - | ** The first [[AP_Statistics_Curriculum_2007_Distrib_MeanVar#Higher_Moments |sample-moment]] for a [[AP_Statistics_Curriculum_2007_Distrib_Binomial#Bernoulli_process |Bernoulli process]] is p=E(Y). Therefore, if the [[EBook#Random_Variables |random variable]] ''X = {# H’s}'' is [[AP_Statistics_Curriculum_2007_Distrib_Binomial |Binomially distributed]], then the expected value of X is ''E(X)=np=8p''. And the sample value | + | ** The first [[AP_Statistics_Curriculum_2007_Distrib_MeanVar#Higher_Moments |sample-moment]] for a [[AP_Statistics_Curriculum_2007_Distrib_Binomial#Bernoulli_process |Bernoulli process]] is p=E(Y). Therefore, if the [[EBook#Random_Variables |random variable]] ''X = {# H’s}'' is [[AP_Statistics_Curriculum_2007_Distrib_Binomial |Binomially distributed]], then the expected value of X is ''E(X)=np=8p''. And the sample value of X is ''Sample#H’s = 5''. Equating the first sample moments yields <math>\hat{8p} \approx 5</math>. Hence, we would estimate the unknown <math>p=P(H) \approx MOM(p)=\hat{p}={5\over 8}</math>. |
* Experimental Solution: We can also use [http://socr.ucla.edu/htmls/SOCR_Experiments.html SOCR Experiments] to demonstrate the MOM estimation technique. You can refer to the [[SOCR_EduMaterials_Activities_CoinSampleExperiment | SOCR Coin Sample Experiment]] for more information of this SOCR applet. The The figure below illustrates flipping a coin 8 times and observing 5 Heads. This is a [[AP_Statistics_Curriculum_2007_Distrib_Binomial | Binomial(n=8, p=0.65)]] distribution. However, let's pretend for a minute that we did '''not''' know the actual ''p=P(H)'' value! So we have a good approximation <math>0.65=p=P(H) \approx MOM(p)=\hat{p}={5\over 8}=0.625</math>. Of course, if we run this experiment again, our MOM estimate for ''p'' would change! | * Experimental Solution: We can also use [http://socr.ucla.edu/htmls/SOCR_Experiments.html SOCR Experiments] to demonstrate the MOM estimation technique. You can refer to the [[SOCR_EduMaterials_Activities_CoinSampleExperiment | SOCR Coin Sample Experiment]] for more information of this SOCR applet. The The figure below illustrates flipping a coin 8 times and observing 5 Heads. This is a [[AP_Statistics_Curriculum_2007_Distrib_Binomial | Binomial(n=8, p=0.65)]] distribution. However, let's pretend for a minute that we did '''not''' know the actual ''p=P(H)'' value! So we have a good approximation <math>0.65=p=P(H) \approx MOM(p)=\hat{p}={5\over 8}=0.625</math>. Of course, if we run this experiment again, our MOM estimate for ''p'' would change! | ||
Revision as of 17:14, 28 May 2008
Contents |
General Advance-Placement (AP) Statistics Curriculum - Method of Moments and Maximum Likelihood Estimation
Suppose we flip a coin 8 times and observe the number of heads (successes) in the outcomes. How would we estimate the true (unknown) probability of a Head (P(H)=?) for this specific coin? There are a number of other similar situations where we need to evaluate, predict or estimate a population (or process) parameter of interest using an observed data sample.
There are many ways to obtain point (value) estimates of various population parameters of interest, using observed data from the specific process we study. The method of moments and the maximum likelihood estimation are among the most popular ones frequently used in practice.
Some practical demonstrations of parameter estimation are shown in the SOCR Modeler Normal and Beta Distribution Model Fitting Activity, which uses the SOCR Modeler applets.
Method of Moments (MOM) Estimation
Parameter estimation using the method of moments is both intuitive and easy to calculate. The idea is to use the sample data to calculate some sample moments and then set these equal to their corresponding population counterparts. Typically the latter involve the parameter(s) that we are interested in estimating and thus we obtain a computationally tractable protocol for their estimation. Summarizing the MOM:
- First: Determine the k parameters of interest and the specific (model) distribution for this process;
- Second: Compute the first k (or more) sample-moments;
- Third: Set the sample-moments equal to the population moments and solve a (linear or non-linear) system of k equations with k unknowns.
MOM Proportion Example
Let's look at the motivational problem we discussed above. We want to flip a coin 8 times, observe the number of heads (successes) in the outcomes and use that to infer the true (unknown) probability of a Head (P(H)=?) for this specific coin.
- Hypothetical solution: Suppose we observe the following sequence of outcomes {T,H,T,H,H,T,H,H}. Using the MOM protocol we obtain:
- There is one parameter of interest p=P(H) and the process is a Binomial experiment.
- The first sample-moment for a Bernoulli process is p=E(Y). Therefore, if the random variable X = {# H’s} is Binomially distributed, then the expected value of X is E(X)=np=8p. And the sample value of X is Sample#H’s = 5. Equating the first sample moments yields
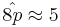 . Hence, we would estimate the unknown
. Hence, we would estimate the unknown 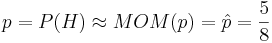 .
.
- Experimental Solution: We can also use SOCR Experiments to demonstrate the MOM estimation technique. You can refer to the SOCR Coin Sample Experiment for more information of this SOCR applet. The The figure below illustrates flipping a coin 8 times and observing 5 Heads. This is a Binomial(n=8, p=0.65) distribution. However, let's pretend for a minute that we did not know the actual p=P(H) value! So we have a good approximation
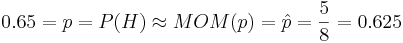 . Of course, if we run this experiment again, our MOM estimate for p would change!
. Of course, if we run this experiment again, our MOM estimate for p would change!

More information about the method of moments for parameter (point) estimation may be found here.
Maximum Likelihood Estimation (MLE)
Maximum likelihood estimation (MLE) is another popular statistical technique for parameter estimation. Modeling distribution parameters using MLE estimation based on observed real world data offers a way of tuning the free parameters of the model to provide an optimum fit. Summarizing the MLE:
Suppose we observe a sample 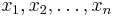 of n values from one distribution with probability density/mass function fθ, and we are trying to estimate the (vector of) parameter(s) θ. We can compute the (multivariate) probability density associated with our observed data,
of n values from one distribution with probability density/mass function fθ, and we are trying to estimate the (vector of) parameter(s) θ. We can compute the (multivariate) probability density associated with our observed data, 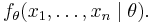
As a function of θ with x1, ..., xn fixed, the likelihood function is:
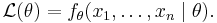
The method of maximum likelihood estimates θ by finding the value of θ that maximizes 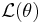 . Thus, the maximum likelihood estimator (MLE) of θ is:
. Thus, the maximum likelihood estimator (MLE) of θ is:
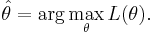
The outcome of a maximum likelihood analysis is the maximum likelihood estimate 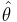 . One typically assumes that the observed data comes are independent and identically distributed (IID) with unknown parameters (θ). This considerably simplifies the problem because the likelihood can then be written as a product of n univariate probability densities:
. One typically assumes that the observed data comes are independent and identically distributed (IID) with unknown parameters (θ). This considerably simplifies the problem because the likelihood can then be written as a product of n univariate probability densities:
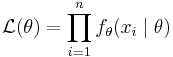
and since maxima are unaffected by monotone transformations, one can take the logarithm of this expression to turn it into a sum:
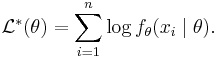
The maximum of this expression can then be found numerically using various optimization algorithms.
Note that the maximum likelihood estimator may not be unique, or is guaranteed to exist.
MLE Proportion Example
Let's look again at the motivational problem of flipping a coin 8 times, observing the number of heads (successes) in the outcomes and using this inferring (based on MLE) the true (unknown) probability of a Head (P(H)=?) for this specific coin.
Suppose again we observe the same sequence of 8 outcomes {T,H,T,H,H,T,H,H}. Using the MLE protocol we obtain:
- Likelihood function:
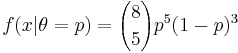
- Log-likelihood function:
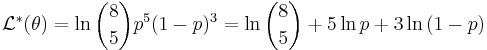 .
.
- Maximize the log-likelihood function by setting its first derivative to zero:
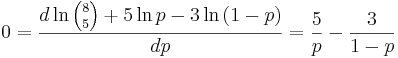 . Thus, 5(1 − p) − 3p = 0, and
. Thus, 5(1 − p) − 3p = 0, and 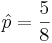 .
.
In this case the MOM(p)=MLE(p), however, this is not true in general.
Normal Mean MLE Estimation Example
Suppose we have observed IID { }={0.5,0.3,0.6,0.1,0.2}, subjects' weights, coming from N(μ,σ2 = 1), with marginal density function f(x | μ). Then the joint density is
}={0.5,0.3,0.6,0.1,0.2}, subjects' weights, coming from N(μ,σ2 = 1), with marginal density function f(x | μ). Then the joint density is  and the likelihood function
and the likelihood function 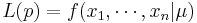 .
.
Of course, we are trying to estimate the average weight for a subject form this population -- i.e., we are trying to find the MLE(μ).
-
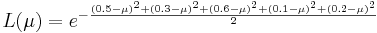
-
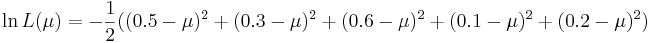
-
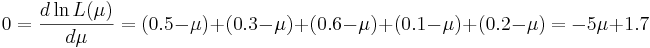
- Thus,
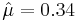
- Validate the this value indeed maximizes the log-likelihood function, i.e.,
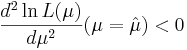 .
.
MOM vs. MLE
- The MOM is inferior to Fisher's MLE method, because maximum likelihood estimators have higher probability of being close to the quantities to be estimated.
- MLE may be intractable in some situations, whereas the MOM estimates can be quickly and easily calculated by hand or using a computer.
- MOM estimates may be used as the first approximations to the solutions of the MLE method, and successive improved approximations may then be found by the Newton-Raphson method. In this respect, the MOM and MLE are symbiotic.
- Sometimes, MOM estimates may be outside of the parameter space; i.e., they are unreliable, which is never a problem with the MLE method.
- MOM estimates are not necessarily sufficient statistics, i.e., they sometimes fail to take into account all relevant information in the sample.
- MOM may be preferred to MLE for estimating some structural parameters (e.g., parameters of a utility function, instead of parameters of a known probability distribution), when appropriate probability distributions are unknown.
Parameter Estimation Examples
The SOCR Modeler and the corresponding SOCR Modeler Activities provide a number of interesting examples of parameter (point) estimation in terms of fitting best models to observed data.
References
- Lecture notes on Statistical Methods in Neuroimaging
- Notes on parameter estimation, expectation maximization and mixture modeling and the corresponding Java applets and activities.
- SOCR Home page: http://www.socr.ucla.edu
Translate this page:
