AP Statistics Curriculum 2007 GLM Corr
From Socr
(→Properties of the Correlation Coefficient) |
|||
| Line 84: | Line 84: | ||
====Hot-dogs dataset==== | ====Hot-dogs dataset==== | ||
Use [[SOCR_EduMaterials_AnalysisActivities_SLR | the Simple Linear Regression]] to compute the correlation between the calories and sodium in the [[SOCR_012708_ID_Data_HotDogs | Hot-dogs dataset]]. | Use [[SOCR_EduMaterials_AnalysisActivities_SLR | the Simple Linear Regression]] to compute the correlation between the calories and sodium in the [[SOCR_012708_ID_Data_HotDogs | Hot-dogs dataset]]. | ||
| + | |||
| + | ====Airfare Example==== | ||
| + | Suppose we have the following bivariate X={airfare} and Y={distance traveled from Washington, DC} measurements: | ||
| + | |||
| + | <center> | ||
| + | {| class="wikitable" style="text-align:center; width:75%" border="1" | ||
| + | |- | ||
| + | | '''Destination''' || '''Distance''' || '''Airfare''' | ||
| + | |- | ||
| + | | Atlanta || 576 || 178 | ||
| + | |- | ||
| + | | Boston || 370 || 138 | ||
| + | |- | ||
| + | | Chicago || 612 || 94 | ||
| + | |- | ||
| + | | Dallas || 1216 || 278 | ||
| + | |- | ||
| + | | Detroit || 409 || 158 | ||
| + | |- | ||
| + | | Denver || 1502 || 258 | ||
| + | |- | ||
| + | | Miami || 946 || 198 | ||
| + | |- | ||
| + | | New Orleans || 998 || 188 | ||
| + | |- | ||
| + | | New York || 189 || 98 | ||
| + | |- | ||
| + | | Orlando || 787 || 179 | ||
| + | |- | ||
| + | | Pittsburgh || 210 || 138 | ||
| + | |- | ||
| + | | St. Louis || 737 || 98 | ||
| + | |}</center> | ||
| + | |||
| + | Use [[SOCR_EduMaterials_AnalysisActivities_SLR | the Simple Linear Regression]] to find the correlation between ticket fare and the distance traveled by passengers. Explain your findings. | ||
| + | |||
===Properties of the Correlation Coefficient=== | ===Properties of the Correlation Coefficient=== | ||
| Line 90: | Line 126: | ||
* The correlation is (almost) linearly invariant: <math>\rho_{(aX+b,Y)} = \sgn(a)\times \rho_{(X,Y)}</math>. If <math>a>0</math>, then <math>\rho_{(aX+b,Y)} = \rho_{(X,Y)}</math>. If <math>a<0</math>, then <math>\rho_{(aX+b,Y)} = -\rho_{(X,Y)}</math>. | * The correlation is (almost) linearly invariant: <math>\rho_{(aX+b,Y)} = \sgn(a)\times \rho_{(X,Y)}</math>. If <math>a>0</math>, then <math>\rho_{(aX+b,Y)} = \rho_{(X,Y)}</math>. If <math>a<0</math>, then <math>\rho_{(aX+b,Y)} = -\rho_{(X,Y)}</math>. | ||
* A trivial correlation, <math>\rho_{X,Y}=0</math> only implies that there is '''no linear relation between X and Y''', but there may be other relations (e.g., quadratic). Thererefore, [[AP_Statistics_Curriculum_2007_Prob_Rules#Statistical_Independence | statistical independence of X and Y]] does imply that <math>\rho_{X,Y}=0</math>, however the converse is false, <math>\rho_{X,Y}=0</math> does not imply independence! | * A trivial correlation, <math>\rho_{X,Y}=0</math> only implies that there is '''no linear relation between X and Y''', but there may be other relations (e.g., quadratic). Thererefore, [[AP_Statistics_Curriculum_2007_Prob_Rules#Statistical_Independence | statistical independence of X and Y]] does imply that <math>\rho_{X,Y}=0</math>, however the converse is false, <math>\rho_{X,Y}=0</math> does not imply independence! | ||
| - | * A high correlation between X and Y does not imply causality (i.e., does not mean that one of the variables causes the observed | + | * A high correlation between X and Y does not imply causality (i.e., does not mean that one of the variables causes the observed behavior in the other. Example, consider X={math scores} and Y={shoe size) for all K-12 students. X and Y are very highly positively correlated, yet higher shoe sizes do not imply better math skills! |
* [http://en.wikipedia.org/wiki/Correlation The complete properties of the Correlation coefficients may be found here]. | * [http://en.wikipedia.org/wiki/Correlation The complete properties of the Correlation coefficients may be found here]. | ||
Revision as of 05:58, 17 February 2008
Contents |
General Advance-Placement (AP) Statistics Curriculum - Correlation
Many biomedical, social, engineering and science applications involve the analysis of relationships, if any, between two or more variables involved in the process of interest. We begin with the simplest of all situations where bivariate data (X and Y) are measured for a process and we are interested on determining the association, relation or an appropriate model for these observations (e.g., fitting a straight line to the pairs of (X,Y) data). If we are successful determining a relationship between X and Y, we can use this model to make predictions - i.e., given a value of X predict a corresponding Y response. Note that in this design, data consists of paired observations (X,Y) - for example, the height and weight of individuals.
Lines in 2D
There are 3 types of lines in 2D planes - Vertical Lines, Horizontal Lines and Oblique Lines. In general, the mathematical representation of lines in 2D is given by equations like aX + bY = c, most frequently expressed as Y = aX + b, provides the line is not vertical.
Recall that there is a one-to-one correspondence between any line in 2D and (linear) equations of the form
- If the line is vertical (X1 = X2): X = X1;
- If the line is horizontal (Y1 = Y2): Y = Y1;
- Otherwise (oblique line):
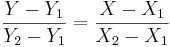 , (for
, (for 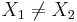 and
and 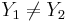 )
)
where (X1,Y1) and (X2,Y2) are two points on the line of interest (2-distinct points in 2D determine a unique line).
- Try drawing the following lines manually and using this applet:
- Y=2X+1
- Y=-3X-5
The Correlation Coefficient
Correlation coefficient (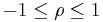 ) is a measure of linear association, or clustering around a line of multivariate data. The main relationship between two variables (X, Y) can be summarized by: (μX,σX), (μY,σY) and the correlation coefficient, denoted by ρ = ρ(X,Y) = R(X,Y).
) is a measure of linear association, or clustering around a line of multivariate data. The main relationship between two variables (X, Y) can be summarized by: (μX,σX), (μY,σY) and the correlation coefficient, denoted by ρ = ρ(X,Y) = R(X,Y).
- If ρ = 1, we have a perfect positive correlation (straight line relationship between the two variables)
- If ρ = 0, there is no correlation (random cloud scatter), i.e., no linear relation between X and Y.
- If ρ = − 1, there is a perfect negative correlation between the variables.
Computing ρ = R(X,Y)
The protocol for computing the correlation involves standardizing, multiplication and averaging.
- In general, for any random variable:
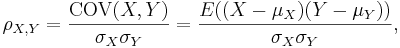
where E is the expected value operator and COV means covariance. Since μX = E(X), σX2 = E(X2) − E2(X) and similarly for Y, we may also write
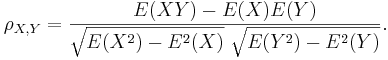
- Sample correlation - we only have sampled data - we replace the (unknown) expectations and standard deviations by their sample analogues (sample-mean and sample-standard deviation) to compute the sample correlation:
- Suppose {
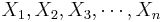 } and {
} and {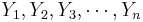 } are bivariate observations of the same process and (μX,σX) and (μY,σY) are the means and standard deviations for the X and Y measurements, respectively.
} are bivariate observations of the same process and (μX,σX) and (μY,σY) are the means and standard deviations for the X and Y measurements, respectively.
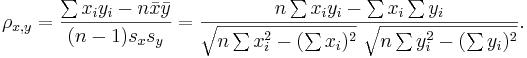
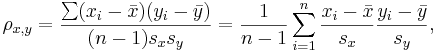
where 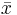 and
and 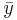 are the sample means of X and Y , sx and sy are the sample standard deviations of X and Y and the sum is from i = 1 to n. We may rewrite this as
are the sample means of X and Y , sx and sy are the sample standard deviations of X and Y and the sum is from i = 1 to n. We may rewrite this as
- Note: The correlation is defined only if both of the standard deviations are finite and both of them are nonzero. It is a corollary of the Cauchy-Schwarz inequality that the correlation is always bound .
Examples
Human weight and height
Suppose we took only 6 of the over 2,000 observations of human weight and height included in this SOCR Dataset.
| Subject Index | Height(xi) in cm | Weight (yi) in kg | 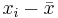 |  | 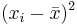 | 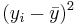 | 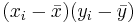
|
| 1 | 167 | 60 | 6 | 4.67 | 36 | 21,82 | 28.02 |
| 2 | 170 | 64 | 9 | 8.67 | 81 | 75.17 | 78.03 |
| 3 | 160 | 57 | -1 | 1.67 | 1 | 2.79 | -1.67 |
| 4 | 152 | 46 | -9 | -9.33 | 81 | 87.05 | 83.97 |
| 5 | 157 | 55 | -4 | -0.33 | 16 | 0.11 | 1.32 |
| 6 | 160 | 50 | -1 | -5.33 | 1 | 28.41 | 5.33 |
| Total | 966 | 332 | 0 | 0 | 216 | 215.33 | 195.0 |
We can easily now compute by hand 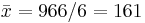 (cm),
(cm), 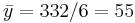 (kg),
(kg), 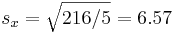 and
and 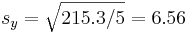 .
.
Therefore, 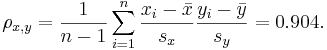
Of course, these calculations become difficult for more than a few paired observations and that is why we use the Simple Linear Regression in SOCR Analyses to compute the correlation and other linear associations in the bivariate case. The image below shows the calculations for the same data shown above in SOCR.

Use the Simple Linear Regression to compute the correlation between the Height and weight in the first 200 measurements in the human weight and height included in this SOCR Dataset.
Hot-dogs dataset
Use the Simple Linear Regression to compute the correlation between the calories and sodium in the Hot-dogs dataset.
Airfare Example
Suppose we have the following bivariate X={airfare} and Y={distance traveled from Washington, DC} measurements:
| Destination | Distance | Airfare |
| Atlanta | 576 | 178 |
| Boston | 370 | 138 |
| Chicago | 612 | 94 |
| Dallas | 1216 | 278 |
| Detroit | 409 | 158 |
| Denver | 1502 | 258 |
| Miami | 946 | 198 |
| New Orleans | 998 | 188 |
| New York | 189 | 98 |
| Orlando | 787 | 179 |
| Pittsburgh | 210 | 138 |
| St. Louis | 737 | 98 |
Use the Simple Linear Regression to find the correlation between ticket fare and the distance traveled by passengers. Explain your findings.
Properties of the Correlation Coefficient
- The correlation is associative operation: ρ(X,Y) = ρ(Y,X)
- The correlation is (almost) linearly invariant:
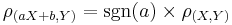 . If a > 0, then ρ(aX + b,Y) = ρ(X,Y). If a < 0, then ρ(aX + b,Y) = − ρ(X,Y).
. If a > 0, then ρ(aX + b,Y) = ρ(X,Y). If a < 0, then ρ(aX + b,Y) = − ρ(X,Y).
- A trivial correlation, ρX,Y = 0 only implies that there is no linear relation between X and Y, but there may be other relations (e.g., quadratic). Thererefore, statistical independence of X and Y does imply that ρX,Y = 0, however the converse is false, ρX,Y = 0 does not imply independence!
- A high correlation between X and Y does not imply causality (i.e., does not mean that one of the variables causes the observed behavior in the other. Example, consider X={math scores} and Y={shoe size) for all K-12 students. X and Y are very highly positively correlated, yet higher shoe sizes do not imply better math skills!
- The complete properties of the Correlation coefficients may be found here.
References
- SOCR Home page: http://www.socr.ucla.edu
Translate this page:
