AP Statistics Curriculum 2007 Hypothesis L Mean
From Socr
(→Example) |
(→Example) |
||
| Line 43: | Line 43: | ||
: <math>T_o = {\overline{x} - \mu_o \over SE(\overline{x})} = {14.77 - 20 \over {{1\over \sqrt{30}} \sqrt{\sum_{i=1}^{30}{(x_i-14.77)^2\over 29}}})}=-1.733</math>. | : <math>T_o = {\overline{x} - \mu_o \over SE(\overline{x})} = {14.77 - 20 \over {{1\over \sqrt{30}} \sqrt{\sum_{i=1}^{30}{(x_i-14.77)^2\over 29}}})}=-1.733</math>. | ||
: <math>P(T_{(df=29)}>T_o=-1.733)=0.047</math>, thus | : <math>P(T_{(df=29)}>T_o=-1.733)=0.047</math>, thus | ||
| - | : the <math>p-value=2\times 0.047= 0.094</math> for this (double-sided) test. Therefore, we '''can not reject''' the null hypothesis at <math>\alpha=0.05</math>! | + | : the <math>p-value=2\times 0.047= 0.094</math> for this (double-sided) test. Therefore, we '''can not reject''' the null hypothesis at <math>\alpha=0.05</math>! The left and right white areas at the tails of the T(df=29) distribution depict graphically the probability of interest, which represents the strenght of the evidence (in the data) against the Null hypothesis. In this case, the cummulative tail area is 0.094, which is larger than the initially set [[AP_Statistics_Curriculum_2007_Hypothesis_Basics | Type I]] error <math>\alpha = 0.05</math> and we can not reject the nul hypothesis. |
<center>[[Image:SOCR_EBook_Dinov_Hypothesis_020508_Fig3.jpg|600px]]</center> | <center>[[Image:SOCR_EBook_Dinov_Hypothesis_020508_Fig3.jpg|600px]]</center> | ||
| - | * You can see use the [http://socr.ucla.edu/htmls/SOCR_Analyses.html SOCR Analyses (One-Sample T-Test)] to carry out these calculations as shown in the figure below | + | * You can see use the [http://socr.ucla.edu/htmls/SOCR_Analyses.html SOCR Analyses (One-Sample T-Test)] to carry out these calculations as shown in the figure below. |
<center>[[Image:SOCR_EBook_Dinov_Hypothesis_020508_Fig2.jpg|600px]]</center> | <center>[[Image:SOCR_EBook_Dinov_Hypothesis_020508_Fig2.jpg|600px]]</center> | ||
Revision as of 19:36, 6 February 2008
Contents |
General Advance-Placement (AP) Statistics Curriculum - Testing a Claim about a Mean: Large Samples
We already saw how to construct point and interval estimates for the population mean in the large sample case. Now, we show how to do hypothesis testing about the mean for large sample-sizes.
Background
- Recall that for a random sample {
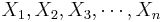 } of the process, the population mean may be estimated by the sample average,
} of the process, the population mean may be estimated by the sample average, 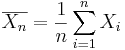 .
.
- For a given small α (e.g., 0.1, 0.05, 0.025, 0.01, 0.001, etc.), the (1 − α)100% Confidence interval for the mean is constructed by
-
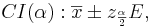
- where the margin of error E is defined as
-
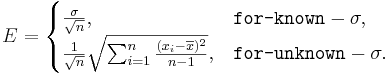
- and
 is the critical value for a Standard Normal distribution at
is the critical value for a Standard Normal distribution at 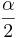 .
.
Hypothesis Testing about a Mean: Large Samples
- Null Hypothesis: Ho:μ = μo (e.g., 0)
- Alternative Research Hypotheses:
- One sided (uni-directional): H1:μ > μo, or Ho:μ < μo
- Double sided:
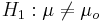
Known Variance
-
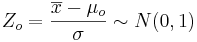 .
.
Unknown Variance
-
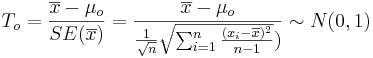 .
.
Example
Let's revisit the number of sentences per advertisement example, where we measure of readability for magazine advertisements. A random sample of the number of sentences found in 30 magazine advertisements is listed below. Suppose we want to test at α = 0.05 a null hypothesis: Ho:μ = 20 against a double-sided research alternative hypothesis: 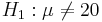 .
.
| 16 | 9 | 14 | 11 | 17 | 12 | 99 | 18 | 13 | 12 | 5 | 9 | 17 | 6 | 11 | 17 | 18 | 20 | 6 | 14 | 7 | 11 | 12 | 5 | 18 | 6 | 4 | 13 | 11 | 12 |
We had the following 2 sample statistics computed earlier
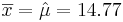
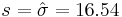
As the population variance is not given, we have to use the T-statistics: 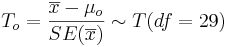
-
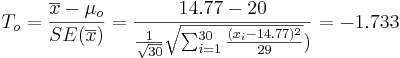 .
.
- P(T(df = 29) > To = − 1.733) = 0.047, thus
- the
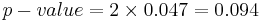 for this (double-sided) test. Therefore, we can not reject the null hypothesis at α = 0.05! The left and right white areas at the tails of the T(df=29) distribution depict graphically the probability of interest, which represents the strenght of the evidence (in the data) against the Null hypothesis. In this case, the cummulative tail area is 0.094, which is larger than the initially set Type I error α = 0.05 and we can not reject the nul hypothesis.
for this (double-sided) test. Therefore, we can not reject the null hypothesis at α = 0.05! The left and right white areas at the tails of the T(df=29) distribution depict graphically the probability of interest, which represents the strenght of the evidence (in the data) against the Null hypothesis. In this case, the cummulative tail area is 0.094, which is larger than the initially set Type I error α = 0.05 and we can not reject the nul hypothesis.

- You can see use the SOCR Analyses (One-Sample T-Test) to carry out these calculations as shown in the figure below.

- This SOCR One Smaple T-test Activity provides additional hands-on demonstrations of one-sample hypothesis testing.
Examples
Cavendish Mean Density of the Earth
A number of famous early experiments of measuring physical constants have later been shown to be biased. in the 1700's Henry Cavendish measured the Mean density of the Earth. Formulate and test null and research hypotheses about these data regarding the now know exact mean-density value = 5.517. These sample statistics may be helpful
- n = 23, sample mean = 5.483, sample SD = 0.1904
| 5.36 | 5.29 | 5.58 | 5.65 | 5.57 | 5.53 | 5.62 | 5.29 | 5.44 | 5.34 | 5.79 | 5.10 | 5.27 | 5.39 | 5.42 | 5.47 | 5.63 | 5.34 | 5.46 | 5.30 | 5.75 | 5.68 | 5.85 |
Hypothesis Testing Summary
Important parts of Hypothesis test conclusions:
- Decision (significance or no significance)
- Parameter of interest
- Variable of interest
- Population under study
- (optional but preferred) P-value
Parallels between Hypothesis Testing and Confidence Intervals
These are different methods for coping with the uncertainty about the true value of a parameter caused by the sampling variation in estimates.
- Confidence intervals: A fixed level of confidence is chosen. We determine a range of possible values for the parameter that are consistent with the data (at the chosen confidence level).
- Hypothesis (Significance) testing: Only one possible value for the parameter, called the hypothesized value, is tested. We determine the strength of the evidence (confidence) provided by the data against the proposition that the hypothesized value is the true value.
- SOCR Home page: http://www.socr.ucla.edu
Translate this page:
