AP Statistics Curriculum 2007 Infer 2Means Dep
From Socr
| Line 1: | Line 1: | ||
==[[AP_Statistics_Curriculum_2007 | General Advance-Placement (AP) Statistics Curriculum]] - Inferences about Two Means: Dependent Samples== | ==[[AP_Statistics_Curriculum_2007 | General Advance-Placement (AP) Statistics Curriculum]] - Inferences about Two Means: Dependent Samples== | ||
| + | |||
| + | In the [[AP_Statistics_Curriculum_2007_Hypothesis_S_Mean | previous chapter we saw how to do significance testing in the case of a single random sample]]. Now, we show how to do hypothesis testing comparing two samples and we begin with the simple case of paired samples. | ||
=== Inferences about Two Means: Dependent Samples=== | === Inferences about Two Means: Dependent Samples=== | ||
| - | + | In all study designs it is always critical to clearly identify whether samples we compare come from dependent or independent populations. There is a general formulation for the significance testing when the samples are independent. The fact that there may be uncountably many differnt types of dependencies prevents us from having a similar analysis protocol for ''all'' dependent sample cases. However, in one sepecific case - paired samples - we have the theory to generalize the significance testing analysis proitocol. Two populations (or samples) are ''dependent because of pairing'' (or paired) if they are linked in some way, usually by a direct relationship. For example, measure the weight of subjects before and after a six month diet. | |
| - | + | ||
| - | === | + | ===Paired Designs=== |
| - | + | These are the most common '''Paired Designs''' where the idea of pairing is that members of a pair are similar to each other with respect to extraneous variables. | |
| - | * | + | *Randomized block experiments with two units per block |
| + | *Observational studies with individually matched controls (e.g., clinical trials of drug efficacy - patient pre vs. post treatment results are compared) | ||
| + | *Repeated (time or treatment affected) measurements on the same individual | ||
| + | *Blocking by time – formed implicitly when replicate measurements are made at different times. | ||
| - | === | + | ===[[AP_Statistics_Curriculum_2007_Estim_L_Mean | Background]]=== |
| - | + | * Recall that for a random sample {<math>X_1, X_2, X_3, \cdots , X_n</math>} of the process, the population mean may be estimated by the sample average, <math>\overline{X_n}={1\over n}\sum_{i=1}^n{X_i}</math>. | |
| - | * | + | * The standard error of <math>\overline{x}</math> is given by <math>{{1\over \sqrt{n}} \sqrt{\sum_{i=1}^n{(x_i-\overline{x})^2\over n-1}}}</math>. |
| - | === | + | ===Paired Analysis Protocol=== |
| - | + | To study paired data we would like to examine the differences between each pair. Suppose {<math>X_1^1, X_2^1, X_3^1, \cdots , X_n^1</math>} and {<math>X_1^2, X_2^2, X_3^2, \cdots , X_n^2</math>} represent to paired samples. The we want to study the difference sample {<math>d_1=X_1^1-X_1^2, d_2=X_2^1-X_2^2, d_3=X_3^1-X_3^2, \cdots , d_n=X_n^1-X_n^2</math>}. Notice the effect of the pairings of each <math>X_i^1</math> and <math>X_i^2</math>. | |
| - | + | Now we can clearly see that the group effect (group differences) are directly represented in the {<math>d_i</math>} sequence. The [[AP_Statistics_Curriculum_2007_Hypothesis_S_Mean#.28Approximately.29_Nornal_Process_with_Unknown_Variance | one-sample T test]] is the proper strategy to analyze the difference sample {<math>d_i</math>}, if the <math>X_i^1</math> and <math>X_i^2</math> samples come from [[AP_Statistics_Curriculum_2007#Chapter_V:_Normal_Probability_Distribution |Normal distributions]]. | |
| - | + | ||
| - | * | + | Because we are focusing on the differences, we can use the same reasoning as we did in the [[AP_Statistics_Curriculum_2007_Hypothesis_S_Mean#.28Approximately.29_Nornal_Process_with_Unknown_Variance |single sample case]] to calculate the standard error (i.e., the standard deviation of the sampling distribution of <math>\overline{d}</math>) of <math>\overline{d}={1\over n}\sum_{i=1}^n{d_i}</math>. |
| - | + | ||
| - | === | + | Thus, the standard error of <math>\overline{d}</math> is given by <math>{{1\over \sqrt{n}} \sqrt{\sum_{i=1}^n{(d_i-\overline{d})^2\over n-1}}}</math>, where <math>d_i=X_i^1-X_i^2, \foreach 1\leq i\leq n</math>. |
| - | + | ||
| + | === Two-Sample Hypothesis Testing about a Mean=== | ||
| + | * Null Hypothesis: <math>H_o: \mu_1-\mu_2=\mu_o</math> (e.g..., <math>\mu_1-\mu_2=0</math>) | ||
| + | * Alternative Research Hypotheses: | ||
| + | ** One sided (uni-directional): <math>H_1: \mu_1 -\mu_2>\mu_o</math>, or <math>H_o: \mu_1-\mu_2<\mu_o</math> | ||
| + | ** Double sided: <math>H_1: \mu_1 - \mu_2 \not= \mu_o</math> | ||
| + | |||
| + | ====Test Statistics==== | ||
| + | * If the two populations that the {<math>X_i_1</math>} and {<math>X_i_2</math>} samples were drawn from are approximately Normal, then the [http://en.wikipedia.org/wiki/Hypothesis_testing#Common_test_statistics Test statistics] is: | ||
| + | : <math>T_o = {\overline{d} - \mu_o \over SE(\overline{d})} = {\overline{x} - \mu_o \over {{1\over \sqrt{n}} \sqrt{\sum_{i=1}^n{(d_i-\overline{d})^2\over n-1}}})} \sim N(0,1)</math>. | ||
| + | |||
| + | ===Example=== | ||
| + | Suppose we measure the thickness of plaque (mm) in the carotid artery of 10 randomly selected patients with [http://www.heartcheckamerica.com/cas_more.htm mild atherosclerotic disease]. Two measurements are taken, thickness before treatment with Vitamin E (baseline) and after two years of taking Vitamin E daily. | ||
| + | |||
| + | *What makes this paired data rather than independent data? | ||
| + | |||
| + | * Why would we want to use pairing in this example? | ||
| + | |||
| + | <center> | ||
| + | {| class="wikitable" style="text-align:center; width:75%" border="1" | ||
| + | |- | ||
| + | ! Subject Before After Difference | ||
| + | |- | ||
| + | | 1 || 0.66 || 0.60 || 0.06 | ||
| + | |- | ||
| + | | 2 || 0.72 || 0.65 || 0.07 | ||
| + | |- | ||
| + | | 3 || 0.85 || 0.79 || 0.06 | ||
| + | |- | ||
| + | | 4 || 0.62 || 0.63 || -0.01 | ||
| + | |- | ||
| + | | 5 || 0.59 || 0.54 || 0.05 | ||
| + | |- | ||
| + | | 6 || 0.63 || 0.55 || 0.08 | ||
| + | |- | ||
| + | | 7 || 0.64 || 0.62 || 0.02 | ||
| + | |- | ||
| + | | 8 || 0.70 || 0.67 || 0.03 | ||
| + | |- | ||
| + | | 9 || 0.73 || 0.68 || 0.05 | ||
| + | |- | ||
| + | | 10 || 0.68 || 0.64 || 0.04 | ||
| + | |- | ||
| + | ! mean || 0.682 || 0.637 || 0.045 | ||
| + | |- | ||
| + | ! sd || 0.0742 || 0.0709 || 0.0264 | ||
| + | |} | ||
| + | </center> | ||
| + | |||
| + | As the population variance is not given, we have to use the [[AP_Statistics_Curriculum_2007_StudentsT |T-statistics]]: <math>T_o = {\overline{x} - \mu_o \over SE(\overline{x})} \sim T(df=9)</math> | ||
| + | : <math>T_o = {\overline{x} - \mu_o \over SE(\overline{x})} = {22.1 - 12 \over {{1\over \sqrt{10}} \sqrt{\sum_{i=1}^{10}{(x_i-22.1)^2\over 9}}})}=1.176</math>. | ||
| + | : <math>p-value=P(T_{(df=9)}>T_o=1.176)=0.134882</math> for this (one-sided) test. Therefore, we '''can not reject''' the null hypothesis at <math>\alpha=0.01</math>! The left white area at the tails of the T(df=9) distribution depict graphically the probability of interest, which represents the strenght of the evidence (in the data) against the Null hypothesis. In this case, this area is 0.134882, which is larger than the initially set [[AP_Statistics_Curriculum_2007_Hypothesis_Basics | Type I]] error <math>\alpha = 0.01</math> and we can not reject the null hypothesis. | ||
| + | <center>[[Image:SOCR_EBook_Dinov_Hypothesis_020508_Fig4.jpg|600px]]</center> | ||
| + | |||
| + | * You can see use the [http://socr.ucla.edu/htmls/SOCR_Analyses.html SOCR Analyses (One-Sample T-Test)] to carry out these calculations as shown in the figure below. | ||
| + | <center>[[Image:SOCR_EBook_Dinov_Hypothesis_020508_Fig5.jpg|600px]]</center> | ||
| + | |||
| + | * This [[SOCR_EduMaterials_AnalysisActivities_OneT | SOCR One Smaple T-test Activity]] provides additional hands-on demonstrations of one-sample hypothesis testing. | ||
| + | |||
| + | ===Examples=== | ||
| - | + | ====Cavendish Mean Density of the Earth==== | |
| + | A number of famous early experiments of measuring physical constants have later been shown to be biased. In the 1700's [http://en.wikipedia.org/wiki/Henry_Cavendish Henry Cavendish] measured the [http://www.jstor.org/view/02610523/ap000022/00a00200/0 Mean density of the Earth]. Formulate and test null and research hypotheses about these data regarding the now know exact mean-density value = 5.517. These sample statistics may be helpful | ||
| + | : n = 23, sample mean = 5.483, sample SD = 0.1904 | ||
| + | <center> | ||
| + | {| class="wikitable" style="text-align:center; width:75%" border="1" | ||
| + | |- | ||
| + | | 5.36 || 5.29 || 5.58 || 5.65 || 5.57 || 5.53 || 5.62 || 5.29 || 5.44 || 5.34 || 5.79 || 5.10 || 5.27 || 5.39 || 5.42 || 5.47 || 5.63 || 5.34 || 5.46 || 5.30 || 5.75 || 5.68 || 5.85 | ||
| + | |} | ||
| + | </center> | ||
<hr> | <hr> | ||
===References=== | ===References=== | ||
| - | |||
<hr> | <hr> | ||
Revision as of 21:39, 9 February 2008
Contents |
General Advance-Placement (AP) Statistics Curriculum - Inferences about Two Means: Dependent Samples
In the previous chapter we saw how to do significance testing in the case of a single random sample. Now, we show how to do hypothesis testing comparing two samples and we begin with the simple case of paired samples.
Inferences about Two Means: Dependent Samples
In all study designs it is always critical to clearly identify whether samples we compare come from dependent or independent populations. There is a general formulation for the significance testing when the samples are independent. The fact that there may be uncountably many differnt types of dependencies prevents us from having a similar analysis protocol for all dependent sample cases. However, in one sepecific case - paired samples - we have the theory to generalize the significance testing analysis proitocol. Two populations (or samples) are dependent because of pairing (or paired) if they are linked in some way, usually by a direct relationship. For example, measure the weight of subjects before and after a six month diet.
Paired Designs
These are the most common Paired Designs where the idea of pairing is that members of a pair are similar to each other with respect to extraneous variables.
- Randomized block experiments with two units per block
- Observational studies with individually matched controls (e.g., clinical trials of drug efficacy - patient pre vs. post treatment results are compared)
- Repeated (time or treatment affected) measurements on the same individual
- Blocking by time – formed implicitly when replicate measurements are made at different times.
Background
- Recall that for a random sample {
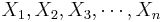 } of the process, the population mean may be estimated by the sample average,
} of the process, the population mean may be estimated by the sample average, 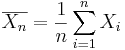 .
.
- The standard error of
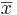 is given by
is given by 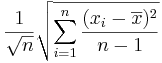 .
.
Paired Analysis Protocol
To study paired data we would like to examine the differences between each pair. Suppose {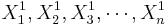 } and {
} and {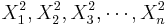 } represent to paired samples. The we want to study the difference sample {
} represent to paired samples. The we want to study the difference sample {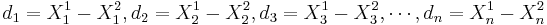 }. Notice the effect of the pairings of each
}. Notice the effect of the pairings of each 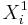 and
and 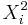 .
.
Now we can clearly see that the group effect (group differences) are directly represented in the {di} sequence. The one-sample T test is the proper strategy to analyze the difference sample {di}, if the and samples come from Normal distributions.
Because we are focusing on the differences, we can use the same reasoning as we did in the single sample case to calculate the standard error (i.e., the standard deviation of the sampling distribution of 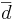 ) of
) of 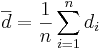 .
.
Thus, the standard error of is given by 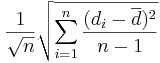 , where Failed to parse (unknown function\foreach): d_i=X_i^1-X_i^2, \foreach 1\leq i\leq n
.
, where Failed to parse (unknown function\foreach): d_i=X_i^1-X_i^2, \foreach 1\leq i\leq n
.
Two-Sample Hypothesis Testing about a Mean
- Null Hypothesis: Ho:μ1 − μ2 = μo (e.g..., μ1 − μ2 = 0)
- Alternative Research Hypotheses:
- One sided (uni-directional): H1:μ1 − μ2 > μo, or Ho:μ1 − μ2 < μo
- Double sided:
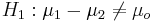
Test Statistics
- If the two populations that the {Failed to parse (PNG conversion failed;
check for correct installation of latex, dvips, gs, and convert): X_i_1 } and {Failed to parse (PNG conversion failed; check for correct installation of latex, dvips, gs, and convert): X_i_2 } samples were drawn from are approximately Normal, then the Test statistics is:
-
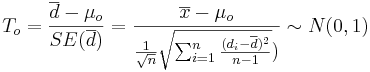 .
.
Example
Suppose we measure the thickness of plaque (mm) in the carotid artery of 10 randomly selected patients with mild atherosclerotic disease. Two measurements are taken, thickness before treatment with Vitamin E (baseline) and after two years of taking Vitamin E daily.
- What makes this paired data rather than independent data?
- Why would we want to use pairing in this example?
| Subject Before After Difference | |||
|---|---|---|---|
| 1 | 0.66 | 0.60 | 0.06 |
| 2 | 0.72 | 0.65 | 0.07 |
| 3 | 0.85 | 0.79 | 0.06 |
| 4 | 0.62 | 0.63 | -0.01 |
| 5 | 0.59 | 0.54 | 0.05 |
| 6 | 0.63 | 0.55 | 0.08 |
| 7 | 0.64 | 0.62 | 0.02 |
| 8 | 0.70 | 0.67 | 0.03 |
| 9 | 0.73 | 0.68 | 0.05 |
| 10 | 0.68 | 0.64 | 0.04 |
| mean | 0.682 | 0.637 | 0.045 |
| sd | 0.0742 | 0.0709 | 0.0264 |
As the population variance is not given, we have to use the T-statistics: 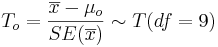
-
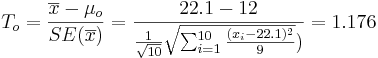 .
.
- p − value = P(T(df = 9) > To = 1.176) = 0.134882 for this (one-sided) test. Therefore, we can not reject the null hypothesis at α = 0.01! The left white area at the tails of the T(df=9) distribution depict graphically the probability of interest, which represents the strenght of the evidence (in the data) against the Null hypothesis. In this case, this area is 0.134882, which is larger than the initially set Type I error α = 0.01 and we can not reject the null hypothesis.

- You can see use the SOCR Analyses (One-Sample T-Test) to carry out these calculations as shown in the figure below.

- This SOCR One Smaple T-test Activity provides additional hands-on demonstrations of one-sample hypothesis testing.
Examples
Cavendish Mean Density of the Earth
A number of famous early experiments of measuring physical constants have later been shown to be biased. In the 1700's Henry Cavendish measured the Mean density of the Earth. Formulate and test null and research hypotheses about these data regarding the now know exact mean-density value = 5.517. These sample statistics may be helpful
- n = 23, sample mean = 5.483, sample SD = 0.1904
| 5.36 | 5.29 | 5.58 | 5.65 | 5.57 | 5.53 | 5.62 | 5.29 | 5.44 | 5.34 | 5.79 | 5.10 | 5.27 | 5.39 | 5.42 | 5.47 | 5.63 | 5.34 | 5.46 | 5.30 | 5.75 | 5.68 | 5.85 |
References
- SOCR Home page: http://www.socr.ucla.edu
Translate this page:
