AP Statistics Curriculum 2007 Infer 2Means Indep
From Socr
(→Small Samples) |
|||
| Line 25: | Line 25: | ||
*'''Significance Testing''': Again, we have a standard null-hypothesis <math>H_o: \mu_X -\mu_Y = \mu_o</math> (e.g., <math>\mu_o=0</math>). Then the test statistics is: | *'''Significance Testing''': Again, we have a standard null-hypothesis <math>H_o: \mu_X -\mu_Y = \mu_o</math> (e.g., <math>\mu_o=0</math>). Then the test statistics is: | ||
: <math>T_o = {\overline{x}-\overline{y}-\mu_o \over SE(\overline{x}-\overline{y})} \sim T(df)</math>. | : <math>T_o = {\overline{x}-\overline{y}-\mu_o \over SE(\overline{x}-\overline{y})} \sim T(df)</math>. | ||
| - | : The ''degrees of freedom'' is: <math>df={( SE^2(\overline{x})+SE^2(\overline{x}))^2 \over {SE^4(\overline{x}) \over n_1-1} + {SE^4(\overline{y}) \over n_2-1} } \approx n_1+n_2-2.</math> Always round | + | : The ''degrees of freedom'' is: <math>df={( SE^2(\overline{x})+SE^2(\overline{x}))^2 \over {SE^4(\overline{x}) \over n_1-1} + {SE^4(\overline{y}) \over n_2-1} } \approx n_1+n_2-2.</math> Always round down the degrees of freedom to the next smaller integer. |
: <math>t_o= {\overline{x}-\overline{y}- \mu_o \over \sqrt{{1\over {n_1}} {\sum_{i=1}^{n_1}{(x_i-\overline{x})^2\over n_1-1}} + {1\over {n_2}} {\sum_{i=1}^{n_2}{(y_i-\overline{y})^2\over n_2-1}}}}</math> | : <math>t_o= {\overline{x}-\overline{y}- \mu_o \over \sqrt{{1\over {n_1}} {\sum_{i=1}^{n_1}{(x_i-\overline{x})^2\over n_1-1}} + {1\over {n_2}} {\sum_{i=1}^{n_2}{(y_i-\overline{y})^2\over n_2-1}}}}</math> | ||
* '''Confidence Intervals''': <math>(1-\alpha)100%</math> confidence interval for <math>\mu_1-\mu_2</math> will be | * '''Confidence Intervals''': <math>(1-\alpha)100%</math> confidence interval for <math>\mu_1-\mu_2</math> will be | ||
: <math>CI(\alpha): \overline{x}-\overline{y} \pm t_{df, {\alpha\over 2}} SE(\overline{x}-\overline{y})= \overline{x}-\overline{y} \pm t_{df, {\alpha\over 2}} \sqrt{{1\over {n_1}} {\sum_{i=1}^{n_1}{(x_i-\overline{x})^2\over n_1-1}} + {1\over {n_2}} {\sum_{i=1}^{n_2}{(y_i-\overline{y})^2\over n_2-1}}}</math>. Note that the <math>SE(\overline{x} -\overline{x})=\sqrt{SE(\overline{x})+SE(\overline{y})}</math>, as the samples are independent. | : <math>CI(\alpha): \overline{x}-\overline{y} \pm t_{df, {\alpha\over 2}} SE(\overline{x}-\overline{y})= \overline{x}-\overline{y} \pm t_{df, {\alpha\over 2}} \sqrt{{1\over {n_1}} {\sum_{i=1}^{n_1}{(x_i-\overline{x})^2\over n_1-1}} + {1\over {n_2}} {\sum_{i=1}^{n_2}{(y_i-\overline{y})^2\over n_2-1}}}</math>. Note that the <math>SE(\overline{x} -\overline{x})=\sqrt{SE(\overline{x})+SE(\overline{y})}</math>, as the samples are independent. | ||
| - | : The ''degrees of freedom'' is: <math>df={( SE^2(\overline{x})+SE^2(\overline{x}))^2 \over {SE^4(\overline{x}) \over n_1-1} + {SE^4(\overline{y}) \over n_2-1} } \approx n_1+n_2-2.</math> Always round | + | : The ''degrees of freedom'' is: <math>df={( SE^2(\overline{x})+SE^2(\overline{x}))^2 \over {SE^4(\overline{x}) \over n_1-1} + {SE^4(\overline{y}) \over n_2-1} } \approx n_1+n_2-2.</math> Always round down the degrees of freedom to the next smaller integer. Also, <math>t_{df, {\alpha\over 2}}</math> is the [[AP_Statistics_Curriculum_2007_Normal_Critical | critical value]] for a [[AP_Statistics_Curriculum_2007_StudentsT |Student's T]] distribution at <math>{\alpha\over 2}</math>. |
| - | + | ===Example=== | |
| + | Nine observations of surface soil [http://en.wikipedia.org/wiki/PH pH] were made at two different locations. Does the data suggest that the true mean soil [http://en.wikipedia.org/wiki/PH pH] values differ for the two locations? Formulate testable hypothesis and make inference about the effect of the treatment at <math>\alpha=0.05</math>. Check any necessary assumptions for the validity of your test. | ||
| + | ====Data in row format==== | ||
| + | <center> | ||
| + | {| class="wikitable" style="text-align:center; width:55%" border="1" | ||
| + | |- | ||
| + | | Location 1 || 8.1,7.89,8,7.85,8.01,7.82,7.99,7.8,7.93 | ||
| + | |- | ||
| + | | Location 2 || 7.85,7.3,7.73,7.27,7.58,7.27,7.5,7.23,7.41 | ||
| + | |} | ||
| + | </center> | ||
| + | |||
| + | ====Data in column format==== | ||
| + | <center> | ||
| + | {| class="wikitable" style="text-align:center; width:55%" border="1" | ||
| + | |- | ||
| + | ! Index || Location 1 || Location 2 | ||
| + | | 1 || 8.10 || 7.85 | ||
| + | | 2 || 7.89 || 7.30 | ||
| + | | 3 || 8.00 || 7.73 | ||
| + | | 4 || 7.85 || 7.27 | ||
| + | | 5 || 8.01 || 7.58 | ||
| + | | 6 || 7.82 || 7.27 | ||
| + | | 7 || 7.99 || 7.50 | ||
| + | | 8 || 7.80 || 7.23 | ||
| + | | 9 || 7.93 || 7.41 | ||
| + | |- | ||
| + | ! Mean || 7.9322 || 7.4600 | ||
| + | |- | ||
| + | ! SD || 0.1005 || 0.2220 | ||
| + | |} | ||
| + | </center> | ||
| + | |||
| + | ====[[AP_Statistics_Curriculum_2007_EDA_Plots |Exploratory Data Analysis]]==== | ||
| + | We begin first by exploring the data visually using various [[AP_Statistics_Curriculum_2007_EDA_Plots | SOCR EDA Tools]]. | ||
| + | |||
| + | * [[SOCR_EduMaterials_Activities_LineChart | Line Chart]] of the two samples | ||
| + | <center>[[Image:SOCR_EBook_Dinov_Infer_2Means_Indep_020908_Fig1.jpg|600px]]</center> | ||
| + | |||
| + | * [[SOCR_EduMaterials_Activities_BoxPlot| Box-And-Whisker Plot]] of the two samples | ||
| + | <center>[[Image:SOCR_EBook_Dinov_Infer_2Means_Indep_020908_Fig2.jpg|600px]]</center> | ||
| + | |||
| + | ====Inference==== | ||
| + | * Null Hypothesis: <math>H_o: \mu_{1}-\mu_{2}=0</math> | ||
| + | * (Two-sided) alternative Research Hypotheses: <math>H_1: \mu_{1} -\mu_{2} \not= 0</math>. | ||
| + | |||
| + | * Test statistics: We can use the sample summary statistics to compute the degrees of freedom and the [[AP_Statistics_Curriculum_2007_Infer_2Means_Dep#Test_Statistics |T-statistic]] | ||
| + | : The ''degrees of freedom'' is: <math>df={( SE^2(\overline{x})+SE^2(\overline{x}))^2 \over {SE^4(\overline{x}) \over n_1-1} + {SE^4(\overline{y}) \over n_2-1} } ={( 0.0335^2+0.074^2)^2 \over {0.0335^4 \over 8} + {0.074^4 \over 8} } = 11.03.</math> So, we round down '''df=11'''. | ||
| + | |||
| + | : <math>t_o= {\overline{x}-\overline{y}- \mu_o \over \sqrt{{1\over {n_1}} {\sum_{i=1}^{n_1}{(x_i-\overline{x})^2\over n_1-1}} + {1\over {n_2}} {\sum_{i=1}^{n_2}{(y_i-\overline{y})^2\over n_2-1}}}} = {7.9322-7.460-0 \over 0.081}=58.27</math>. | ||
| + | |||
| + | : <math>p-value=P(T_{(df=11)}>T_o=5.827)=0.000216</math> for this (one-sided) test. Therefore, we '''can reject''' the null hypothesis at <math>\alpha=0.05</math>! The left white area at the tails of the T(df=9) distribution depict graphically the probability of interest, which represents the strenght of the evidence (in the data) against the Null hypothesis. In this case, this area is 0.000216, which is much smaller than the initially set [[AP_Statistics_Curriculum_2007_Hypothesis_Basics | Type I]] error <math>\alpha = 0.05</math> and we reject the null hypothesis. | ||
| + | <center>[[Image:SOCR_EBook_Dinov_Infer_2Means_Dep_020908_Fig4.jpg|600px]]</center> | ||
| + | |||
| + | * You can also use the [http://socr.ucla.edu/htmls/SOCR_Analyses.html SOCR Analyses (One-Sample T-Test)] to carry out these calculations as shown in the figure below. | ||
| + | <center>[[Image:SOCR_EBook_Dinov_Infer_2Means_Dep_020908_Fig5.jpg|600px]]</center> | ||
| + | |||
| + | * This [[SOCR_EduMaterials_AnalysisActivities_OneT | SOCR One Smaple T-test Activity]] provides additional hands-on demonstrations of the one-sample hypothesis testing for the difference in paired experiments. | ||
| + | |||
| + | * <math>95%=(1-0.05)100%</math> (<math>\alpha=0.05</math>) Confidence interval (before-after): | ||
| + | : <math>CI(\mu_{before}-\mu_{after})</math>: <math>\overline{d} \pm t_{\alpha\over 2} SE(\overline {d}) = 0.045 \pm 1.833 \times 0.00833 = [0.0297 ; 0.0603].</math> | ||
| + | |||
| + | ====Conclusion==== | ||
| + | These data show that the true mean thickness of plaque after two years of treatment with Vitamin E is statistically significantly different than before the treatment (p =0.000216). In other words, vitamin E appears to be an effective in changing carotid artery plaque after treatment. The practical effect does appear to be < 60 microns; however, this may be clinically sufficient and justify patient treatment. | ||
| + | |||
| + | ====Paired test Validity==== | ||
| + | Both the confidence intervals and the hypothesis testing methods in the paired design require Normality of both samples. If these parametric assumptions are invalid we must use a [[AP_Statistics_Curriculum_2007_NonParam_2MedianPair | not-parametric (distribution free test)]], even if the latter is less powerful. | ||
| + | |||
| + | The plots below indicate that Normal assumptions are not unreasonable for these data, and hence we may be justified in using the one-sample T-test in this case. | ||
| + | |||
| + | * [[AP_Statistics_Curriculum_2007_Normal_Prob#Assessing_Normality |Quantile-Quantile Data-Data plot]] of the two datasets: | ||
| + | <center>[[Image:SOCR_EBook_Dinov_Infer_2Means_Dep_020908_Fig6.jpg|600px]]</center> | ||
| + | |||
| + | * [[AP_Statistics_Curriculum_2007_Normal_Prob#Assessing_Normality | QQ-Normal plot]] of the before data: | ||
| + | <center>[[Image:SOCR_EBook_Dinov_Infer_2Means_Dep_020908_Fig7.jpg|600px]]</center> | ||
<hr> | <hr> | ||
Revision as of 05:32, 10 February 2008
Contents |
General Advance-Placement (AP) Statistics Curriculum - Inferences about Two Means: Independent Samples
In the previous section we discussed the inference on two paired random samples. Now, we show how to do inference on two independent samples.
Indepenent Samples Designs
Independent samples designs refer to design of experiments or observations where all measurements are individually independent from each other within their groups and the groups are independent. The groups may be drawn from different populations with different distribution characteristics.
Background
- Recall that for a random sample {
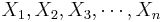 } of the process, the population mean may be estimated by the sample average,
} of the process, the population mean may be estimated by the sample average, 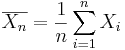 .
.
- The standard error of
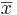 is given by
is given by 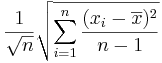 .
.
Analysis Protocol for Independent Designs
To study independent samples we would like to examine the differences between two group means. Suppose {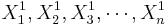 } and {
} and {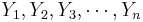 } represent the two independent samples. Then we want to study the differences of the two group means relative to the internal sample variations. If the two samples were drawn from populations that had different centers, then we would expect that the two sample averages will be distinct.
} represent the two independent samples. Then we want to study the differences of the two group means relative to the internal sample variations. If the two samples were drawn from populations that had different centers, then we would expect that the two sample averages will be distinct.
Large Samples
- Significance Testing: We have a standard null-hypothesis Ho:μX − μY = μo (e.g., μo = 0). Then the test statistics is:
-
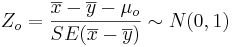 .
.
-
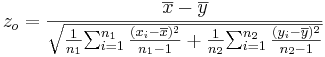
- Confidence Intervals: (1 − α)100% confidence interval for μ1 − μ2 will be
-
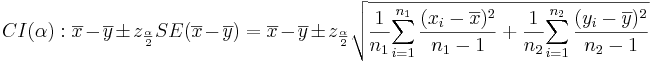 . Note that the
. Note that the 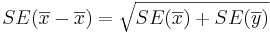 , as the samples are independent. Also,
, as the samples are independent. Also,  is the critical value for a Standard Normal distribution at
is the critical value for a Standard Normal distribution at 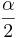 .
.
Small Samples
- Significance Testing: Again, we have a standard null-hypothesis Ho:μX − μY = μo (e.g., μo = 0). Then the test statistics is:
-
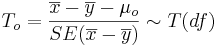 .
.
- The degrees of freedom is:
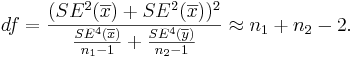 Always round down the degrees of freedom to the next smaller integer.
Always round down the degrees of freedom to the next smaller integer.
-
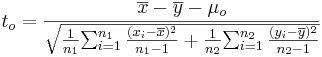
- Confidence Intervals: (1 − α)100% confidence interval for μ1 − μ2 will be
-
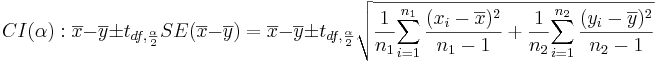 . Note that the , as the samples are independent.
. Note that the , as the samples are independent.
- The degrees of freedom is: Always round down the degrees of freedom to the next smaller integer. Also,
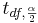 is the critical value for a Student's T distribution at .
is the critical value for a Student's T distribution at .
Example
Nine observations of surface soil pH were made at two different locations. Does the data suggest that the true mean soil pH values differ for the two locations? Formulate testable hypothesis and make inference about the effect of the treatment at α = 0.05. Check any necessary assumptions for the validity of your test.
Data in row format
| Location 1 | 8.1,7.89,8,7.85,8.01,7.82,7.99,7.8,7.93 |
| Location 2 | 7.85,7.3,7.73,7.27,7.58,7.27,7.5,7.23,7.41 |
Data in column format
| Index | Location 1 | Location 2 | 1 | 8.10 | 7.85 | 2 | 7.89 | 7.30 | 3 | 8.00 | 7.73 | 4 | 7.85 | 7.27 | 5 | 8.01 | 7.58 | 6 | 7.82 | 7.27 | 7 | 7.99 | 7.50 | 8 | 7.80 | 7.23 | 9 | 7.93 | 7.41 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Mean | 7.9322 | 7.4600 | |||||||||||||||||||||||||||
| SD | 0.1005 | 0.2220 |
Exploratory Data Analysis
We begin first by exploring the data visually using various SOCR EDA Tools.
- Line Chart of the two samples

- Box-And-Whisker Plot of the two samples

Inference
- Null Hypothesis: Ho:μ1 − μ2 = 0
- (Two-sided) alternative Research Hypotheses:
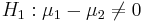 .
.
- Test statistics: We can use the sample summary statistics to compute the degrees of freedom and the T-statistic
- The degrees of freedom is:
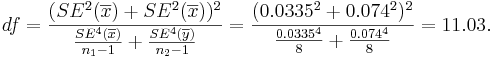 So, we round down df=11.
So, we round down df=11.
-
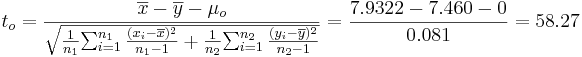 .
.
- p − value = P(T(df = 11) > To = 5.827) = 0.000216 for this (one-sided) test. Therefore, we can reject the null hypothesis at α = 0.05! The left white area at the tails of the T(df=9) distribution depict graphically the probability of interest, which represents the strenght of the evidence (in the data) against the Null hypothesis. In this case, this area is 0.000216, which is much smaller than the initially set Type I error α = 0.05 and we reject the null hypothesis.

- You can also use the SOCR Analyses (One-Sample T-Test) to carry out these calculations as shown in the figure below.

- This SOCR One Smaple T-test Activity provides additional hands-on demonstrations of the one-sample hypothesis testing for the difference in paired experiments.
- 95% = (1 − 0.05)100% (α = 0.05) Confidence interval (before-after):
- CI(μbefore − μafter):
![\overline{d} \pm t_{\alpha\over 2} SE(\overline {d}) = 0.045 \pm 1.833 \times 0.00833 = [0.0297 ; 0.0603].](/socr/uploads/math/2/5/6/25608769a5219a56b2273efc7c03f0c9.png)
Conclusion
These data show that the true mean thickness of plaque after two years of treatment with Vitamin E is statistically significantly different than before the treatment (p =0.000216). In other words, vitamin E appears to be an effective in changing carotid artery plaque after treatment. The practical effect does appear to be < 60 microns; however, this may be clinically sufficient and justify patient treatment.
Paired test Validity
Both the confidence intervals and the hypothesis testing methods in the paired design require Normality of both samples. If these parametric assumptions are invalid we must use a not-parametric (distribution free test), even if the latter is less powerful.
The plots below indicate that Normal assumptions are not unreasonable for these data, and hence we may be justified in using the one-sample T-test in this case.
- Quantile-Quantile Data-Data plot of the two datasets:

- QQ-Normal plot of the before data:

References
- SOCR Home page: http://www.socr.ucla.edu
Translate this page:
