AP Statistics Curriculum 2007 IntroDesign
From Socr
(→Replication) |
(→Orthogonality) |
||
| Line 23: | Line 23: | ||
===Orthogonality=== | ===Orthogonality=== | ||
| - | Orthogonality allows division of complex relations | + | Orthogonality allows division of complex relations and variation into separate (independent/orthogonal) contrasts, or factors, that can be studied efficiently and autonomously. Often, these contrasts may be represented by vectors, where sets of orthogonal contrasts are uncorrelated and may be independently distributed. Independence implies that each orthogonal contrast provides complementary information to other contrasts (i.e., other treatments). The goal is to completely decompose the variance or the relations of the observed measurements into independent components (e.g., like [http://en.wikipedia.org/wiki/Taylor_expansion Taylor expansion] allowing polynomial decomposition of smooth functions, where the polynomial base functions are easy to differentiate, integrate, etc.) This will, of course, allow easier interpretation of the statistical analysis and the findings of the study. |
==Model Validation== | ==Model Validation== | ||
Revision as of 18:34, 28 June 2010
General Advance-Placement (AP) Statistics Curriculum - Design and Experiments
Contents |
Design of Experiments
Design of experiments refers of the blueprint for planning a study or experiment, performing the data collection protocol and controlling the study parameters for accuracy and consistency. Design of experiments only makes sense in studies where variation, chance and uncertainly are present and unavoidable. Data, or information, is typically collected in regard to a specific process or phenomenon being studied to investigate the effects of some controlled variables (independent variables or predictors) on other observed measurements (responses or dependent variables). Both types of variables are associated with specific observational units (living beings, components, objects, materials, etc.)
Approach
The following are the most common components used in Experimental Design:
Comparison
To make inference about effects, associations or predictions, one typically has to compare different groups subjected to distinct conditions. This allows contrasting observed responses and underlying group differences that may ultimately lead to inference on relationships and influences between controlled and observed variables.
Randomization
The second fundamental design principle is randomization. It requires that we make allocation of (controlled variables) treatments to units using some random mechanism. This simply guarantees that the effects resulted are the units, but not incorporated in the model, equidistributed amongst all groups. Therefore it is unlikely to significantly affect our group comparisons at the end of the statistical inference or analysis (as these effects, if present, will be similar within each group).
Experimental vs. Observational Studies
There are many situations, where randomized experiments, albeit desirable, are impractical. Therefore, we cannot deduce causality or effects of various treatments on the response measurement. Observational studies are retrospective or prospective studies where the investigator does not have control over randomization of treatments to subject, or units. In these cases, the subjects or units fall naturally within a treatment group. Examples of such observational studies include studies of smoking effects on cancer and use of parachutes to prevent death and major trauma related to gravitational pull.
Replication
All measurements, observations or data collected are subject to variation, as there are no completely deterministic processes. As we try to make inference about the process that generated the observed data (not the sample data itself, even though our statistical analysis is data-driven and based on the observed measurements), the more data we collect (unbiased) the stronger our inference is likely to be. Therefore, repeated measurements intuitively would allow it to tame the variability associated with the phenomenon we study.
Blocking
Blocking is related to randomization. The difference is that we use blocking when we know a priori of certain effects of the observational units on the response measurements (e.g., when studying the effects of hormonal treatments on humans, gender plays a significant role). We arrange units into groups (blocks) that are similar to one another when we design an experiment in which certain unit characteristics are known to affect the response measurements. Blocking reduces known and irrelevant sources of variation between units and allows greater precision in the estimation of the source of variation in the study.
Orthogonality
Orthogonality allows division of complex relations and variation into separate (independent/orthogonal) contrasts, or factors, that can be studied efficiently and autonomously. Often, these contrasts may be represented by vectors, where sets of orthogonal contrasts are uncorrelated and may be independently distributed. Independence implies that each orthogonal contrast provides complementary information to other contrasts (i.e., other treatments). The goal is to completely decompose the variance or the relations of the observed measurements into independent components (e.g., like Taylor expansion allowing polynomial decomposition of smooth functions, where the polynomial base functions are easy to differentiate, integrate, etc.) This will, of course, allow easier interpretation of the statistical analysis and the findings of the study.
Model Validation
All of the components in the approach/methods section need to be validated but the major one is the independence assumption.
Computational Resources: Internet-based SOCR Tools
Examples & hands-on activities
A study of aortic valve-sparing repair*
- This study sought to establish whether there was a difference in outcome after aortic valve repair with autologous pericardial leaflet extension in acquired versus congenital valvular disease. In this study, 128 patients underwent reparative aortic valve surgery at UCLA from 1997 through 2005 for acquired or congenital aortic valve disease. The acquired group (43/128) (34%) had a mean age of 56.4
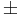 20.3 years (range, 7.8—84.6 years) and the congenital group (85/128) (66%) had a mean age of 16.9 19.2 years (range, 0.3—82 years). The endpoints of the study were mortality and reoperation rates.
20.3 years (range, 7.8—84.6 years) and the congenital group (85/128) (66%) had a mean age of 16.9 19.2 years (range, 0.3—82 years). The endpoints of the study were mortality and reoperation rates.
- In this case the units are heart disease patients. These were split into two groups (acquired or congenital) and blocked by gender (male/female). The treatment allied on the two groups was aortic valve repair with autologous pericardial leaflet extension.
Problems
References
- David De La Zerda, Oved Cohen, Michael C. Fishbein, Jonah Odim, Carlos A Calderon, Diana Hekmat, Ivo Dinov and Hillel Laks. Aortic valve-sparing repair with autologous pericardial leaflet extension has a greater early re-operation rate in congenital versus acquired valve disease. European Journal of Cardio-Thoracic Surgery, February 2007; 31: 256-260 . PMID: 17196393, doi:10.1016/j.ejcts.2006.11.027.
- Gordon Smith, and Jill Pell. (2008) Parachute use to prevent death and major trauma related to gravitational challenge: systematic review of randomised controlled trials. BMJ 2003;327:1459-1461 (20 December), doi:10.1136/bmj.327.7429.1459
- SOCR Home page: http://www.socr.ucla.edu
Translate this page:
