AP Statistics Curriculum 2007 Limits LLN
From Socr
| Line 1: | Line 1: | ||
==[[AP_Statistics_Curriculum_2007 | General Advance-Placement (AP) Statistics Curriculum]] - The Law of Large Numbers== | ==[[AP_Statistics_Curriculum_2007 | General Advance-Placement (AP) Statistics Curriculum]] - The Law of Large Numbers== | ||
| - | === | + | === Motivation=== |
| - | + | Suppose we conduct independently the same experiment over and over again. And assume we are interested in the relative frequency of occurrence of one event whose probability to be observed at each experiment is ''p''. Then the ratio of the observed frequency of that event to the total number of repetitions converges towards ''p'' as the number of (identical and independent) experiments increases. This is an informal statement of the Law of Large Numbers (LLN). | |
| - | + | ||
| - | + | For a more concrete example suppose we study the average height of a class of 100 students. Compared to the average height of 3 randomly chosen students from this class, the average height of 10 randomly chosen students is most likely closer to the real average height of all 100 students. This is true because the sample of 10 is a larger number than the sample of only 3 and better represents the entire class. At one extreme, a sample of 99 of the 100 students will produce a sample average height almost exactly the same as the average height for all 100 students. On the other extreme, sampling a single student will be an extremely variant estimate of the overall class average weight. | |
| - | + | ||
| - | + | ===The Law of Large Numbers (LLN)=== | |
| + | The [http://en.wikipedia.org/wiki/Law_of_large_numbers complete formal statements of the LLN are discussed here]. | ||
| - | === | + | It is generally necessary to draw the parallels between the formal LLN statements (in terms of sample averages) and the frequent interpretations of the LLN (in terms of probabilities of various events). Suppose we observe the same process independently multiple times. Assume a binarized (dichotomous) function of the outcome of each trial is of interest (e.g., failure may denote the event that the continuous voltage measure < 0.5V, and the complement, success, that voltage ≥ 0.5V – this is the situation in electronic chips which binarize electric currents to 0 or 1). Researchers are often interested in the event of observing a success at a given trial or the number of successes in an experiment consisting of multiple trials. Let’s denote ''p=P(success)'' at each trial. Then, the ratio of the total number of successes to the number of trials (''n'') is the average <math>\overline{X_n}={1\over n}\sum_{i=1}^n{X_i}</math>, where <math>X_i = \begin{cases}0,& \texttt{failure},\\ |
| - | + | 1,& \texttt{success}.\end{cases}</math> represents the outcome of the i<sup>th</sup> trial. Thus, <math>\overline{X_n}=\hat{p}</math>, the ratio of the observed frequency of that event to the total number of repetitions, estimates the true ''p=P(success)''. Therefore, <math>\hat{p}</math> converges towards ''p'' as the number of (identical and independent) trials increases. | |
| - | + | ===SOCR LLN Activity=== | |
| + | The [[SOCR_EduMaterials_Activities_LawOfLargeNumbers | complete SOCR CLT Activity is availabel here]]. | ||
| - | + | Go to [http://socr.ucla.edu/htmls/SOCR_Experiments.html SOCR Experiments] and select the '''Coin Toss LLN Experiment''' from the drop-down list of experiments in the top-left panel. This applet consists of a control toolbar on the top followed by a graph panel in the middle and a results table at the bottom. Use the toolbar to flip coins one at a time, 10, 100, 1,000 at a time or continuously! The toolbar also allows you to stop or reset an experiment and select the probability of Heads ('''p''') using the slider. The graph panel in the middle will dynamically plot the values of the two variables of interest (''proportion of heads'' and ''difference of Heads and Tails''). The outcome table at the bottom presents the summaries of all trials of this experiment. | |
| - | + | ||
| - | === | + | ===LLN Application=== |
| - | + | One demonstration of the law of large numbers provides practical algorithms for estimation of [http://en.wikipedia.org/wiki/Transcendental_number transcendental numbers]. The two most popular transcendental numbers are [http://en.wikipedia.org/wiki/Pi <math>\pi</math>] and [http://en.wikipedia.org/wiki/E_%28mathematical_constant%29 ''e'']. | |
| - | + | The [[SOCR_EduMaterials_Activities_Uniform_E_EstimateExperiment | SOCR E-Estimate Experiment]] provides the complete details of this simulation. In a nutshell, we can estimate the value of the [http://en.wikipedia.org/wiki/E_%28mathematical_constant%29 natural number e] using random sampling from Uniform distribution. Suppose <math>X_1, X_2, \cdots, X_n</math> are drawn from [http://www.socr.ucla.edu/htmls/SOCR_Distributions.html uniform distribution on (0, 1)] and define <math>U= {\operatorname{argmin}}_n { \left (X_1+X_2+...+X_n > 1 \right )}</math>, note that all <math>X_i \ge 0</math>. | |
| - | + | ||
| - | + | ||
| - | + | ||
| - | + | Now, the expected value <math>E(U) = e \approx 2.7182</math>. Therefore, by LLN, taking averages of <math>\left \{ U_1, U_2, U_3, ..., U_k \right \}</math> values, each computed from random samples <math>X_1, X_2, ..., X_n \sim U(0,1)</math> as described above, will provide a more accurate estimate (as <math>k \rightarrow \infty</math>) of the natural number ''e''. | |
| + | |||
| + | The '''Uniform E-Estimate Experiment''', part of [http://www.socr.ucla.edu/htmls/SOCR_Experiments.html SOCR Experiments], provides a hands-on demonstration of how the LLN facilitates stochastic simulation-based estimation of ''e''. | ||
| + | |||
| + | <center>[[Image:SOCR_Activities_Uniform_E_EstimateExperiment_Dinov_121907_Fig1.jpg|400px]]</center> | ||
<hr> | <hr> | ||
Revision as of 00:34, 3 February 2008
Contents |
General Advance-Placement (AP) Statistics Curriculum - The Law of Large Numbers
Motivation
Suppose we conduct independently the same experiment over and over again. And assume we are interested in the relative frequency of occurrence of one event whose probability to be observed at each experiment is p. Then the ratio of the observed frequency of that event to the total number of repetitions converges towards p as the number of (identical and independent) experiments increases. This is an informal statement of the Law of Large Numbers (LLN).
For a more concrete example suppose we study the average height of a class of 100 students. Compared to the average height of 3 randomly chosen students from this class, the average height of 10 randomly chosen students is most likely closer to the real average height of all 100 students. This is true because the sample of 10 is a larger number than the sample of only 3 and better represents the entire class. At one extreme, a sample of 99 of the 100 students will produce a sample average height almost exactly the same as the average height for all 100 students. On the other extreme, sampling a single student will be an extremely variant estimate of the overall class average weight.
The Law of Large Numbers (LLN)
The complete formal statements of the LLN are discussed here.
It is generally necessary to draw the parallels between the formal LLN statements (in terms of sample averages) and the frequent interpretations of the LLN (in terms of probabilities of various events). Suppose we observe the same process independently multiple times. Assume a binarized (dichotomous) function of the outcome of each trial is of interest (e.g., failure may denote the event that the continuous voltage measure < 0.5V, and the complement, success, that voltage ≥ 0.5V – this is the situation in electronic chips which binarize electric currents to 0 or 1). Researchers are often interested in the event of observing a success at a given trial or the number of successes in an experiment consisting of multiple trials. Let’s denote p=P(success) at each trial. Then, the ratio of the total number of successes to the number of trials (n) is the average 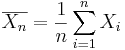 , where
, where 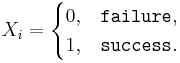 represents the outcome of the ith trial. Thus,
represents the outcome of the ith trial. Thus, 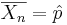 , the ratio of the observed frequency of that event to the total number of repetitions, estimates the true p=P(success). Therefore,
, the ratio of the observed frequency of that event to the total number of repetitions, estimates the true p=P(success). Therefore, 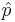 converges towards p as the number of (identical and independent) trials increases.
converges towards p as the number of (identical and independent) trials increases.
SOCR LLN Activity
The complete SOCR CLT Activity is availabel here.
Go to SOCR Experiments and select the Coin Toss LLN Experiment from the drop-down list of experiments in the top-left panel. This applet consists of a control toolbar on the top followed by a graph panel in the middle and a results table at the bottom. Use the toolbar to flip coins one at a time, 10, 100, 1,000 at a time or continuously! The toolbar also allows you to stop or reset an experiment and select the probability of Heads (p) using the slider. The graph panel in the middle will dynamically plot the values of the two variables of interest (proportion of heads and difference of Heads and Tails). The outcome table at the bottom presents the summaries of all trials of this experiment.
LLN Application
One demonstration of the law of large numbers provides practical algorithms for estimation of transcendental numbers. The two most popular transcendental numbers are π and e.
The SOCR E-Estimate Experiment provides the complete details of this simulation. In a nutshell, we can estimate the value of the natural number e using random sampling from Uniform distribution. Suppose 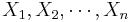 are drawn from uniform distribution on (0, 1) and define
are drawn from uniform distribution on (0, 1) and define 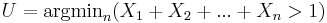 , note that all
, note that all 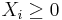 .
.
Now, the expected value 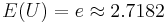 . Therefore, by LLN, taking averages of
. Therefore, by LLN, taking averages of 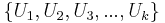 values, each computed from random samples
values, each computed from random samples 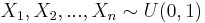 as described above, will provide a more accurate estimate (as
as described above, will provide a more accurate estimate (as 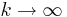 ) of the natural number e.
) of the natural number e.
The Uniform E-Estimate Experiment, part of SOCR Experiments, provides a hands-on demonstration of how the LLN facilitates stochastic simulation-based estimation of e.

References
- TBD
- SOCR Home page: http://www.socr.ucla.edu
Translate this page:
