AP Statistics Curriculum 2007 GLM Predict
From Socr
(added a link to the Problems set) |
|||
| (One intermediate revision not shown) | |||
| Line 3: | Line 3: | ||
=== Inference on Linear Models === | === Inference on Linear Models === | ||
| - | Suppose we have again ''n'' pairs ''(X,Y)'', {<math>X_1, X_2, X_3, \cdots, X_n</math>} and {<math>Y_1, Y_2, Y_3, \cdots, Y_n</math>}, of observations of the same process. | + | Suppose we have again ''n'' pairs ''(X,Y)'', {<math>X_1, X_2, X_3, \cdots, X_n</math>} and {<math>Y_1, Y_2, Y_3, \cdots, Y_n</math>}, of observations of the same process. In the [[AP_Statistics_Curriculum_2007_GLM_Regress |previous section, we discussed how to fit a line to the data]]. The main question is how to determine the best line? |
====[[AP_Statistics_Curriculum_2007_GLM_Corr#Airfare_Example |Airfare Example]]==== | ====[[AP_Statistics_Curriculum_2007_GLM_Corr#Airfare_Example |Airfare Example]]==== | ||
| - | We can see from the [[SOCR_EduMaterials_Activities_ScatterChart |scatterplot]] that [[AP_Statistics_Curriculum_2007_GLM_Corr#Airfare_Example | greater distance is associated with higher airfare]]. In other words, airports that tend to be further from Baltimore tend to | + | We can see from the [[SOCR_EduMaterials_Activities_ScatterChart |scatterplot]] that [[AP_Statistics_Curriculum_2007_GLM_Corr#Airfare_Example | greater distance is associated with higher airfare]]. In other words, airports that tend to be further from Baltimore tend to have more expensive airfare. To decide on the best fitting line, we use the '''least-squares method''' to fit the least squares (regression) line. |
<center>[[Image:SOCR_EBook_Dinov_GLM_Regr_021708_Fig1.jpg|500px]]</center> | <center>[[Image:SOCR_EBook_Dinov_GLM_Regr_021708_Fig1.jpg|500px]]</center> | ||
====Confidence Interval Estimating of the Slope and Intercept of Linear Model==== | ====Confidence Interval Estimating of the Slope and Intercept of Linear Model==== | ||
| - | The parameters (''a'' and ''b'') of the linear regression line, <math>Y = a + bX</math>, are estimated using [http://en.wikipedia.org/wiki/Ordinary_Least_Squares Least Squares]. The least squares technique finds the line that minimizes the sum of the squares of the regression '''residuals''', <math>\hat{\varepsilon_i}=\hat{y}_{i}-y_i</math>, <math> \sum_{i=1}^N {\hat{\varepsilon_i}^2} = \sum_{i=1}^N (\hat{y}_{i}-y_i)^2 </math>, where <math>y_i</math> and <math>\hat{y}_{i}=a+bx_i</math> are the observed and the predicted values of ''Y'' for <math>x_i</math> | + | The parameters (''a'' and ''b'') of the linear regression line, <math>Y = a + bX</math>, are estimated using [http://en.wikipedia.org/wiki/Ordinary_Least_Squares Least Squares]. The least squares technique finds the line that minimizes the sum of the squares of the regression '''residuals''', <math>\hat{\varepsilon_i}=\hat{y}_{i}-y_i</math>, <math> \sum_{i=1}^N {\hat{\varepsilon_i}^2} = \sum_{i=1}^N (\hat{y}_{i}-y_i)^2 </math>, where <math>y_i</math> and <math>\hat{y}_{i}=a+bx_i</math> are the observed and the predicted values of ''Y'' for <math>x_i</math>. |
The minimization problem can be solved using calculus, by finding the first order partial derivatives and setting them equal to zero. The solution gives the slope and y-intercept of the regressions line: | The minimization problem can be solved using calculus, by finding the first order partial derivatives and setting them equal to zero. The solution gives the slope and y-intercept of the regressions line: | ||
| Line 22: | Line 22: | ||
: <math> \hat{a} = \bar{y} - \hat{b} \bar{x} </math> | : <math> \hat{a} = \bar{y} - \hat{b} \bar{x} </math> | ||
| - | If the error terms are Normally distributed, the estimate of the slope coefficient has a normal distribution with mean | + | If the error terms are Normally distributed, the estimate of the slope coefficient has a normal distribution with mean equals to '''b''' and '''standard error''' given by: |
: <math> s_ \hat{b} = \sqrt { {1\over (N-2)} \frac {\sum_{i=1}^N \hat{\varepsilon_i}^2} {\sum_{i=1}^N (x_i - \bar{x})^2} }</math>. | : <math> s_ \hat{b} = \sqrt { {1\over (N-2)} \frac {\sum_{i=1}^N \hat{\varepsilon_i}^2} {\sum_{i=1}^N (x_i - \bar{x})^2} }</math>. | ||
| Line 30: | Line 30: | ||
:<math> [ \hat{b} - s_ \hat{b} t_{(\alpha/2, N-2)},\hat{b} + s_ \hat{b} t_{(\alpha/2, N-2)}] </math> | :<math> [ \hat{b} - s_ \hat{b} t_{(\alpha/2, N-2)},\hat{b} + s_ \hat{b} t_{(\alpha/2, N-2)}] </math> | ||
| - | In other words, if there is | + | In other words, if there is an 1 mile increase in distance the airfare will go up by between $0.054 and $0.180. |
* '''Significance testing''': If X is not useful for predicting Y, then the true slope is zero. In a hypothesis test ,our status quo null hypothesis would be that there is no relationship between X and Y | * '''Significance testing''': If X is not useful for predicting Y, then the true slope is zero. In a hypothesis test ,our status quo null hypothesis would be that there is no relationship between X and Y | ||
Current revision as of 20:48, 28 June 2010
Contents |
General Advance-Placement (AP) Statistics Curriculum - Variation and Prediction Intervals
Inference on Linear Models
Suppose we have again n pairs (X,Y), {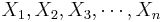 } and {
} and {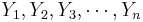 }, of observations of the same process. In the previous section, we discussed how to fit a line to the data. The main question is how to determine the best line?
}, of observations of the same process. In the previous section, we discussed how to fit a line to the data. The main question is how to determine the best line?
Airfare Example
We can see from the scatterplot that greater distance is associated with higher airfare. In other words, airports that tend to be further from Baltimore tend to have more expensive airfare. To decide on the best fitting line, we use the least-squares method to fit the least squares (regression) line.

Confidence Interval Estimating of the Slope and Intercept of Linear Model
The parameters (a and b) of the linear regression line, Y = a + bX, are estimated using Least Squares. The least squares technique finds the line that minimizes the sum of the squares of the regression residuals, 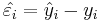 ,
, 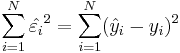 , where yi and
, where yi and 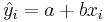 are the observed and the predicted values of Y for xi.
are the observed and the predicted values of Y for xi.
The minimization problem can be solved using calculus, by finding the first order partial derivatives and setting them equal to zero. The solution gives the slope and y-intercept of the regressions line:
- Regression line Slope:
-
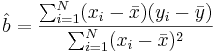
-
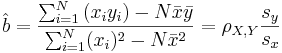 , where ρX,Y is the correlation coefficient.
, where ρX,Y is the correlation coefficient.
- Y-intercept:
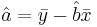
If the error terms are Normally distributed, the estimate of the slope coefficient has a normal distribution with mean equals to b and standard error given by:
-
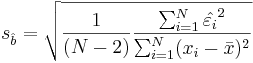 .
.
- A confidence interval for b can be created using a T-distribution with N-2 degrees of freedom:
![[ \hat{b} - s_ \hat{b} t_{(\alpha/2, N-2)},\hat{b} + s_ \hat{b} t_{(\alpha/2, N-2)}]](/socr/uploads/math/9/7/f/97fb851896b79e5d8eb45162cd0c6390.png)
In other words, if there is an 1 mile increase in distance the airfare will go up by between $0.054 and $0.180.
- Significance testing: If X is not useful for predicting Y, then the true slope is zero. In a hypothesis test ,our status quo null hypothesis would be that there is no relationship between X and Y
- Hypotheses: Ho:b = 0 vs.
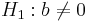 (or H1:b > 0 or H1:b < 0).
(or H1:b > 0 or H1:b < 0).
- Test-statistics:
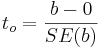 , where
, where 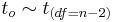 is the T-Distribution.
is the T-Distribution.
Example
For the distance vs. airfare example, we can compute the standard error of the slope coefficient (b), SE(b)
-
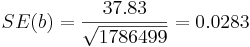 .
.
- Then a 95% confidence interval for b is given by:
- CI(b):
![b \pm t_{(\alpha/2, df=10)}SE(b)=0.11738 \pm 2.228\times 0.02832=[0.054 , 0.180].](/socr/uploads/math/b/9/1/b91659086a64a9cde01e916a03d8ed75.png)
- Significance testing:
-
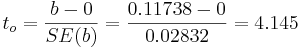 and p − value = 0.002.
and p − value = 0.002.
Earthquake Example
Use the SOCR Earthquake Dataset to formulate and test a research hypothesis about the slope of the best-leaner fit between the Longitude and the Latitude of the California Earthquakes since 1900. You can see the SOCR Geomap of these Earthquakes. The image below shows how to use the Simple Linear regression in SOCR Analyses to calculate the regression line and make inference on the slope.

Problems
- SOCR Home page: http://www.socr.ucla.edu
Translate this page:
