AP Statistics Curriculum 2007 Infer BiVar
From Socr
| Line 1: | Line 1: | ||
==[[AP_Statistics_Curriculum_2007 | General Advance-Placement (AP) Statistics Curriculum]] - Comparing Two Variances== | ==[[AP_Statistics_Curriculum_2007 | General Advance-Placement (AP) Statistics Curriculum]] - Comparing Two Variances== | ||
| - | + | In the [[AP_Statistics_Curriculum_2007_Hypothesis_Var | section on inference about the variance and the standard deviation]] we already learned how to do inference on either of these two population paparemters. Now we discuss the comparison of the variances (or standard deviations) using data randomly sampled from two different populations. | |
| - | + | ||
| - | + | ||
| - | === | + | === [[AP_Statistics_Curriculum_2007_Estim_Var | Background]]=== |
| - | + | Recall that the [[AP_Statistics_Curriculum_2007_EDA_Var | sample-variance (s<sup>2</sup>)]] is an unbiased point estimate for the population variance <math>\sigma^2</math>, and similarly, the [[AP_Statistics_Curriculum_2007_EDA_Var | sample-standard-deviation (''s'')]] is a point estimate for the population-standard-deviation <math>\sigma</math>. | |
| - | + | The sample-variance is roughly [http://en.wikipedia.org/wiki/Chi_square_distribution Chi-square distributed]: | |
| + | : <math>\chi_o^2 = {(n-1)s^2 \over \sigma^2} \sim \Chi_{(df=n-1)}^2</math> | ||
| - | === | + | ===Comparing Two Variances (<math>\sigma_1^2 = \sigma_2^2</math>?)=== |
| - | + | Suppose we study two populations which are approximately Normally distributed, and we take a random sample from each population, {<math>X_1, X_2, X_3, \cdots, X_n</math>} and {<math>Y_1, Y_2, Y_3, \cdots, Y_k</math>}. Recall that <math>{(n-1) s_1^2 \over \sigma_1^2}</math> and <math>{(n-1) s_2^2 \over \sigma_2^2}</math> have <math>\Chi^2_{(df=n - 1)}</math> and <math>\Chi^2_{(df=k - 1)}</math> distributions. We are interested in assessing <math>H_o: \sigma_1^2 = \sigma_2^2</math> vs. <math>H_1: \sigma_1^2 \not= \sigma_2^2</math>, where <math>s_1</math> and <math>\sigma_1</math>, and <math>s_2</math> and <math>\sigma_2</math> and the sample and the population standard deviations for the two samples, respectively. | |
| - | + | Notice that the [http://mathworld.wolfram.com/Chi-SquaredDistribution.html Chi-square distribution] is not symmetric (it is positively skewed). You can visualize the Chi-Square distribution and compute all critical values either using the [http://socr.ucla.edu/htmls/SOCR_Distributions.html SOCR Chi-Square Distribution] or using the [http://socr.ucla.edu/Applets.dir/Normal_T_Chi2_F_Tables.htm SOCR Chi-square distribution calculator]. | |
| - | + | The [http://mathworld.wolfram.com/F-Distribution.html Fisher's F distribution], and the corresponding F-test, is used to test if the variances of two populations are equal. Depending on the alternative hypothesis, we can use either a two-tailed test or a one-tailed test. The two-tailed version tests against an alternative that the standard deviations are not equal (<math>H_1: \sigma_1^2 \not= \sigma_2^2</math>). The one-tailed version only tests in one direction (<math>H_1: \sigma_1^2 < \sigma_2^2</math> or <math>H_1: \sigma_1^2 > \sigma_2^2</math>). The choice is determined by the [[AP_Statistics_Curriculum_2007_IntroDesign | study design]] before any data is analyzed. For example, if a modification to an existent medical treatment is proposed, we may only be interested in knowing if the new treatment is more consistent and less variable than the established medical intervention. | |
| - | + | ||
| - | = | + | * '''Test Statistic''': <math>F_o = {\sigma_1^2 \over \sigma_2^2}</math> |
| - | + | The higher the deviation of this ratio away from 1, the stronger the evidence for unequal population variances. | |
| - | * | + | * Inference: Suppose we test at significance level <math>\alpha=0.05</math>. Then the hypothesis that the two standard deviations are equal is rejected if the test statistics is outside this interval |
| + | : <math>H_1: \sigma_1^2 > \sigma_2^2</math>: If <math>F_o > F(\alpha,df_1=n_1-1,df_2=n_2-1)</math> | ||
| + | |||
| + | : <math>H_1: \sigma_1^2 < \sigma_2^2</math>: If <math>F_o < F(1-\alpha,df_1=n_1-1,df_2=n_2-1)</math> | ||
| + | |||
| + | : <math>H_1: \sigma_1^2 \not= \sigma_2^2</math>: If <math>F_o < F(1-\alpha/2,df_1=n_1-1,df_2=n_2-1)</math> or <math>F_o > F(\alpha/2,df_1=n_1-1,df_2=n_2-1)</math>, | ||
| + | |||
| + | where <math>F(\alpha,df_1=n_1-1,df_2=n_2-1)</math> is the critical value of the [http://socr.ucla.edu/htmls/SOCR_Distributions.html F distribution] with ''degrees of freedom for the numerator and denominator'', <math>df_1=n_1-1,df_2=n_2-1</math>, respectively. | ||
| + | |||
| + | In the image below the left and right critical regions are white with <math>F(\alpha,df_1=n_1-1,df_2=n_2-1)</math> and <math>F(1-\alpha,df_1=n_1-1,df_2=n_2-1)</math> representing the lower and upper, respectively, critical values. In this example of <math>F(df_1=12, df_2=15)</math>, the left and right critical values at <math>\alpha/2=0.025</math> are <math>F(\alpha/2=0.025,df_1=9,df_2=14)=0.314744</math> and <math>F(1-\alpha/2=0.975,df_1=9,df_2=14)=2.96327</math>, respectively. | ||
| + | |||
| + | <center>[[Image:SOCR_EBook_Dinov_Infer_BiVar_021608_Fig1.jpg|500px]]</center> | ||
| + | ===Comparing Two Standard Deviations (<math>\sigma_1 = \sigma_2</math>?)=== | ||
| + | As the standard deviation is just the square root of the variance (<math>\sigma = |\sqrt{\sigma^2}|</math>), we do significance testing for the standard deviation analogously. | ||
| + | |||
| + | For Normally distributed random variables, given <math>H_o: \sigma = \sigma_o</math> vs. <math>H_1: \sigma \not= \sigma_o</math> , then <math>{(n-1) s^2 \over \sigma_o^2}</math> has a <math>\Chi^2_{(df=n - 1)}</math> distribution, where [[AP_Statistics_Curriculum_2007_EDA_Var |<math>s^2</math> is the square of the sample standard deviation]]. | ||
| + | |||
===Hands-on activities=== | ===Hands-on activities=== | ||
| - | + | * Formulate appropriate hypotheses and assess the significance of the evidence to reject the null hypothesis for the population standard deviation (<math>\sigma</math>) assuming the observations below represent a random sample from the liquid content (in fluid ounces) of 16 beverage cans and can be considered as Normally distributed. Use a 90% level of confidence (<math>\alpha=0.1</math>). | |
| + | <center> | ||
| + | {| class="wikitable" style="text-align:center; width:75%" border="1" | ||
| + | |- | ||
| + | | 14.816 || 14.863 || 14.814 || 14.998 || 14.965 || 14.824 || 14.884 || 14.838 || 14.916 || 15.021 || 14.874 || 14.856 || 14.860 || 14.772 || 14.980 || 14.919 | ||
| + | |} | ||
| + | </center> | ||
| + | |||
| + | * Hypotheses: <math>H_o: \sigma = 0.06 (\sigma_o)</math> vs. <math>H_1: \sigma \not= 0.06</math> . | ||
| + | |||
| + | * Get the sample statistics from [http://socr.ucla.edu/htmls/SOCR_Charts.html SOCR Charts] (e.g., Index Plot); Sample-Mean=14.8875; Sample-SD=0.072700298, Sample-Var=0.005285333. | ||
| + | <center>[[Image:SOCR_EBook_Dinov_Estim_Var_020408_Fig3.jpg|500px]]</center> | ||
| + | |||
| + | * Identify the degrees of freedom (<math>df=n-1=15</math>). | ||
| + | |||
| + | * Test Statistics: <math>\Chi_o^2 = {(n-1)s^2 \over \sigma_o^2} \sim \Chi_{(df=n-1)}^2.</math> | ||
| + | |||
| + | * Significance Inference: <math>\chi_o^2 = {15\times 0.005285333 \over 0.06^2}=22.022221</math> | ||
| + | : P-value=<math>P(\Chi_{(df=n-1)}^2 > \chi_o^2) = 0.107223</math>. This p-value does not indicate strong evidence in the data to reject a possible population standard deviation of 0.06. | ||
| + | |||
| + | <center>[[Image:SOCR_EBook_Dinov_Hypothesis_020508_Fig8.jpg|500px]]</center> | ||
| + | |||
| + | ===More examples=== | ||
| + | |||
| + | * You randomly select and measure the contents of 15 bottles of cough syrup. The results (in fluid ounces) are shown. Formulate and test hypotheses about the standard deviation (<math>\sigma_o=0.025</math>) assuming the contents of these cough syrup bottles are Normally distributed. Is there data-driven evidence suggesting that the standard-deviation of the fluids in the bottles is not at an acceptable level? | ||
| + | <center> | ||
| + | {| class="wikitable" style="text-align:center; width:75%" border="1" | ||
| + | |- | ||
| + | | 4.211 || 4.246 || 4.269 || 4.241 || 4.260 || 4.293 || 4.189 || 4.248 || 4.220 || 4.239 || 4.253 || 4.209 || 4.300 || 4.256 || 4.290 | ||
| + | |} | ||
| + | </center> | ||
| + | |||
| + | * The gray whale has the longest annual migration distance of any mammal. Gray whales leave Baja, California, and western Mexico in the spring, migrating to the Bering and Chukchi seas for the summer months. Tracking a sample of 50 whales for a year provided a sample mean migration distance of 11,064 miles with a standard deviation of 860 miles. Assume that the population of migration distances is Normally distributed to formulate and test hypotheses for the population standard deviation (<math>\sigma_o=500</math>). | ||
| - | * | + | * Use the [[SOCR_012708_ID_Data_HotDogs | hot-dogs dataset]] to formulate and test hypotheses about the population standard deviation of the sodium content in the poultry hot-dogs (<math>\sigma_o=70</math>). |
<hr> | <hr> | ||
Revision as of 21:40, 16 February 2008
Contents |
General Advance-Placement (AP) Statistics Curriculum - Comparing Two Variances
In the section on inference about the variance and the standard deviation we already learned how to do inference on either of these two population paparemters. Now we discuss the comparison of the variances (or standard deviations) using data randomly sampled from two different populations.
Background
Recall that the sample-variance (s2) is an unbiased point estimate for the population variance σ2, and similarly, the sample-standard-deviation (s) is a point estimate for the population-standard-deviation σ.
The sample-variance is roughly Chi-square distributed:
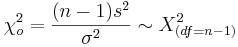
Comparing Two Variances (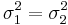 ?)
?)
Suppose we study two populations which are approximately Normally distributed, and we take a random sample from each population, {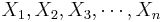 } and {
} and {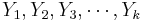 }. Recall that
}. Recall that 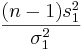 and
and 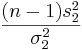 have
have 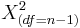 and
and 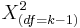 distributions. We are interested in assessing
distributions. We are interested in assessing 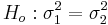 vs.
vs. 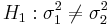 , where s1 and σ1, and s2 and σ2 and the sample and the population standard deviations for the two samples, respectively.
, where s1 and σ1, and s2 and σ2 and the sample and the population standard deviations for the two samples, respectively.
Notice that the Chi-square distribution is not symmetric (it is positively skewed). You can visualize the Chi-Square distribution and compute all critical values either using the SOCR Chi-Square Distribution or using the SOCR Chi-square distribution calculator.
The Fisher's F distribution, and the corresponding F-test, is used to test if the variances of two populations are equal. Depending on the alternative hypothesis, we can use either a two-tailed test or a one-tailed test. The two-tailed version tests against an alternative that the standard deviations are not equal (). The one-tailed version only tests in one direction (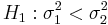 or
or 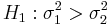 ). The choice is determined by the study design before any data is analyzed. For example, if a modification to an existent medical treatment is proposed, we may only be interested in knowing if the new treatment is more consistent and less variable than the established medical intervention.
). The choice is determined by the study design before any data is analyzed. For example, if a modification to an existent medical treatment is proposed, we may only be interested in knowing if the new treatment is more consistent and less variable than the established medical intervention.
- Test Statistic:
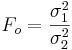
The higher the deviation of this ratio away from 1, the stronger the evidence for unequal population variances.
- Inference: Suppose we test at significance level α = 0.05. Then the hypothesis that the two standard deviations are equal is rejected if the test statistics is outside this interval
- : If Fo > F(α,df1 = n1 − 1,df2 = n2 − 1)
- : If Fo < F(1 − α,df1 = n1 − 1,df2 = n2 − 1)
- : If Fo < F(1 − α / 2,df1 = n1 − 1,df2 = n2 − 1) or Fo > F(α / 2,df1 = n1 − 1,df2 = n2 − 1),
where F(α,df1 = n1 − 1,df2 = n2 − 1) is the critical value of the F distribution with degrees of freedom for the numerator and denominator, df1 = n1 − 1,df2 = n2 − 1, respectively.
In the image below the left and right critical regions are white with F(α,df1 = n1 − 1,df2 = n2 − 1) and F(1 − α,df1 = n1 − 1,df2 = n2 − 1) representing the lower and upper, respectively, critical values. In this example of F(df1 = 12,df2 = 15), the left and right critical values at α / 2 = 0.025 are F(α / 2 = 0.025,df1 = 9,df2 = 14) = 0.314744 and F(1 − α / 2 = 0.975,df1 = 9,df2 = 14) = 2.96327, respectively.

Comparing Two Standard Deviations (σ1 = σ2?)
As the standard deviation is just the square root of the variance (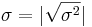 ), we do significance testing for the standard deviation analogously.
), we do significance testing for the standard deviation analogously.
For Normally distributed random variables, given Ho:σ = σo vs. 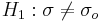 , then
, then 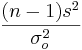 has a distribution, where s2 is the square of the sample standard deviation.
has a distribution, where s2 is the square of the sample standard deviation.
Hands-on activities
- Formulate appropriate hypotheses and assess the significance of the evidence to reject the null hypothesis for the population standard deviation (σ) assuming the observations below represent a random sample from the liquid content (in fluid ounces) of 16 beverage cans and can be considered as Normally distributed. Use a 90% level of confidence (α = 0.1).
| 14.816 | 14.863 | 14.814 | 14.998 | 14.965 | 14.824 | 14.884 | 14.838 | 14.916 | 15.021 | 14.874 | 14.856 | 14.860 | 14.772 | 14.980 | 14.919 |
- Hypotheses: Ho:σ = 0.06(σo) vs.
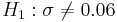 .
.
- Get the sample statistics from SOCR Charts (e.g., Index Plot); Sample-Mean=14.8875; Sample-SD=0.072700298, Sample-Var=0.005285333.

- Identify the degrees of freedom (df = n − 1 = 15).
- Test Statistics:
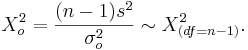
- Significance Inference:
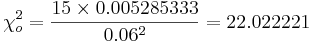
- P-value=
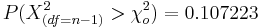 . This p-value does not indicate strong evidence in the data to reject a possible population standard deviation of 0.06.
. This p-value does not indicate strong evidence in the data to reject a possible population standard deviation of 0.06.

More examples
- You randomly select and measure the contents of 15 bottles of cough syrup. The results (in fluid ounces) are shown. Formulate and test hypotheses about the standard deviation (σo = 0.025) assuming the contents of these cough syrup bottles are Normally distributed. Is there data-driven evidence suggesting that the standard-deviation of the fluids in the bottles is not at an acceptable level?
| 4.211 | 4.246 | 4.269 | 4.241 | 4.260 | 4.293 | 4.189 | 4.248 | 4.220 | 4.239 | 4.253 | 4.209 | 4.300 | 4.256 | 4.290 |
- The gray whale has the longest annual migration distance of any mammal. Gray whales leave Baja, California, and western Mexico in the spring, migrating to the Bering and Chukchi seas for the summer months. Tracking a sample of 50 whales for a year provided a sample mean migration distance of 11,064 miles with a standard deviation of 860 miles. Assume that the population of migration distances is Normally distributed to formulate and test hypotheses for the population standard deviation (σo = 500).
- Use the hot-dogs dataset to formulate and test hypotheses about the population standard deviation of the sodium content in the poultry hot-dogs (σo = 70).
References
- TBD
- SOCR Home page: http://www.socr.ucla.edu
Translate this page:
